رگرسيون و همبستگی خطی – بخش 1
13 دی 1400
دقیقه
در مقاله قبلی به تحليل فراوانی داده ها پرداختیم. در این فصل به آموزش رگرسيون و همبستگی خطی (بخش اول)، در ادامه سری مقالات آموزشی آمار به زبان ساده می پردازیم.

آخرین بهروزرسانی: 24 دی 1401
در مقاله قبلی به تحليل فراوانی داده ها پرداختیم. در این فصل به آموزش رگرسيون و همبستگی خطی (بخش اول)، در ادامه سری مقالات آموزشی آمار به زبان ساده می پردازیم.
مقدمه
آيا مي توان اظهار داشت دانشجویاني كه بيشترين زمان خود را صرف مطالعه كرده اند بيشترين نمرات را در امتحانات دريافت خواهند كرد و به همين صورت آيا كساني كه كمترين نمرات را كسب مي كنند كمترين ميزان مطالعه را دارند؟ آنچه در ايجا مطرح است اين است كه آيا متغير ميزان مطالعه رابطه اي با متغير عملكرد امتحاني دارد. اگر چنين چيزي دريافته شود بيان مي شود كه ميان دو متغير همبستگي مثبت وجود دارد، بدين معني كه مشابه با افزايش نمرات يك متغير، نمرات متغير ديگر نيز افزايش مي يابد.
گاهي اوقات متغيرها به صورتي هستند كه با افزايش يكي ديگري كاهش يافته كه در اصطلاح گفته مي شود همبستگي منفي دارند. به عنوان مثال احتمال اينكه همبستگي منفي ميان كشيدن سيگار و سلامتي وجود دارد بدين معني كه افرادي كه سيگار مي كشند از سلامتي كمتري برخودارند. در صورتيكه ميان دو متغير همبستگي وجود داشته باشد مي توان از آن جهت پيش بيني مقدار عددي يك متغير با بكارگيري رابطه ي آن با متغير ديگر استفاده كرد. در اين فصل به در ارتباط با چگونگي توليد يك معادله ي رگرسيوني كه اجازه ي همچين كاري را مي دهد صحبت خواهد شد. در صورتيكه دو متغير هيچگونه رابطه اي با هم نداشته باشند گفته مي شود كه دو متغير ناهم بسته هستند و تغيير در يكي موجب ايجاد تغيير در پيش بيني ديگري نمي شود.
به عنوان يك مثال داده هاي زير كه نتیجه ی بدست آمده در طول مدت ده سال اول دانشجویان دانشگاه است را مورد بررسی قرار می دهیم. این داده ها مربوط به مدت زمانی که دانشجویان صرف مطالعه می کنند است (به طور متوسط در یک هفته در طول بازه ی زمانی یک سال) به همراه نمره ی کسب شده توسط آنها در پایان سال (از 100). آیا این داده ها نشانی از همبستگی دارند؟
با مشاهده ی بصری نتایج به نظر می رسد که یک همبستگی مثبت برقرار باشد، اما بررسی دقیق تر توسط رسم نمودار پراکنش داده ها امکانپذیر است که در آن محورها بیانگر متغیرها هستند. شکل 20.1 نمودار پراکنش نتایج را به تصویر کشیده است.
باید توجه داشت که در این نمودار نقاط به صورت تصادفی پراکنده نشده اند (که همچین انتظاری در مورد داده هایی که هیچگونه همبستگی ای ندارند طبیعی به نظر می رسد) اما زمانی که به صورت گروهی بررسی شوند نشان از نوعی همبستگی دارند. (برای درک بهتر تصور کنید تکه ای از یک کاغذ را جهت پوشش همگی و یا بیشتر نقاط موجود در نمودار برش داده اید. در این حالت این کار را با استفاده از یک نوار نسبتاً باریک از کاغذ می توان انجام داد.)
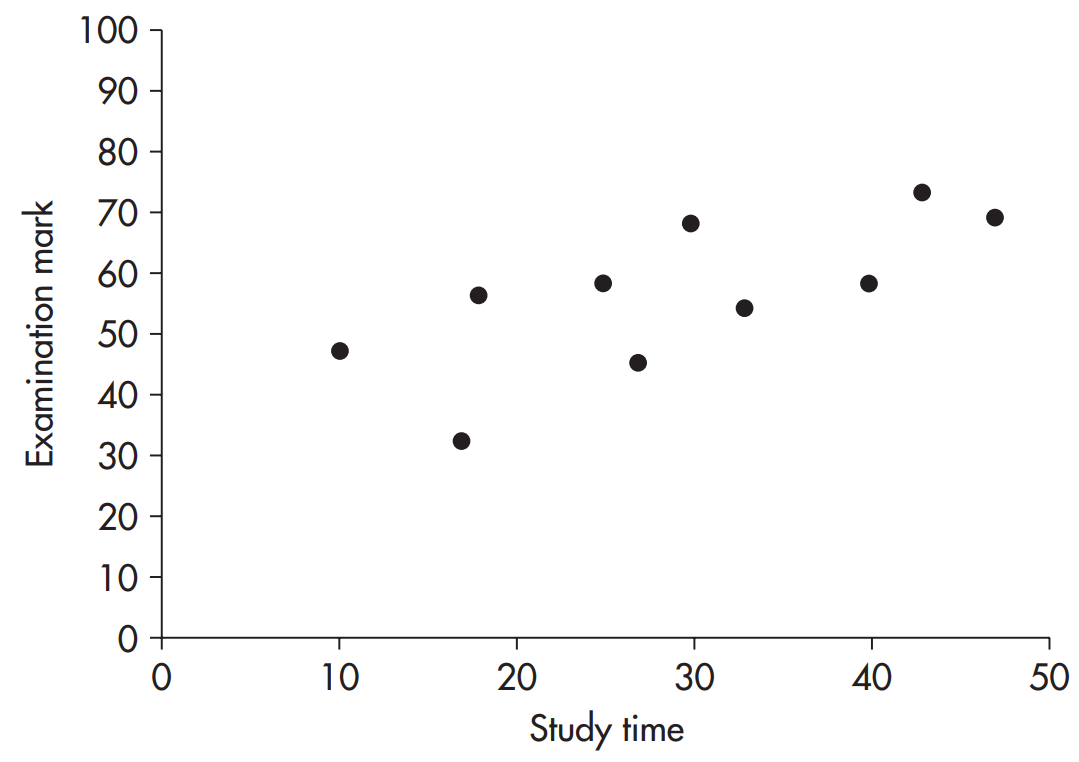
نمودار 1.20 نمودار پراکنش زمان مطالعه در برابر عملکرد آزمون
پس از انجام این کار در مورد مواردی چون خطاهای تصادفی باید بحث کرد؛ بدین صورت که نقاطی که در طول خط که در واقع خط رگرسیونی است چه خطایی تولید می کنند و این خط رگرسیونی را به چه صورت باید به داده ها برازش داد به گونه ای که بهترین برازش ممکن به داده ها باشد. در بسیاری موارد اما نه همیشه، فرض می شود که بهترین خط برازش یک خط مستقیم است و زمانی که چنین فرضی پایه ریزی می شود در واقع فرض کرده ایم که نوعی همبستگی خطی وجود داشته و می بایست رگرسیون خطی محاسبه گردد که در حقیقت همان مدل خطی برای متغیرهایی است که در راستای یک خط مستقیم با هم ارتباط دارند. (فصل 23 در ارتباط با مدل های خطی مشاهده شود). این امر در مورد داده های مثال ذکر شده منطقی به نظر می رسد زیرا نقاط نمودار به صورت گروهی روی یک خط مستقیم قرار گرفته اند. در صورتیکه نقاط در امتداد یک منحنی قرار گیرند باز هم گفته می شود که همبستگی وجود دارد اما نه از نوع خطی. در این کتاب فقط همبستگی و رگرسیون خطی بررسی می شوند.
آنچه که برای انجام این کار لازم است یافتن راهی جهت اندازه گیری میزان همبستگی است. اگر کلیه ی نقاط کاملاً در طول یک خط مستقیم قرار گیرند همبستگی کاملی برقرار است. همبستگی ای مانند آنچه که در شکل 20.1 به دلیل اینکه نقاط تاحدودی به صورت گسترده پراکنده شده اند یک همبستگی کامل نیست اما نسبتاً می توان گفت که روی نوار باریکی قرار دارند و همبستگی منطقی ای را ایجاد کرده اند به طوریکه استنباط می شود که نقاط روی خطی مستقیم قرار گرفته اند منتها با خطاهای تصادفی. هر چقدر پراکندگی نقاط بیشتر شود همبستگی نیز ضعیف تر می شود تا جاییکه گفته شود نقاط به صورت کاملاً تصادفی پراکنده شده اند و هیچگونه همبستگی ای میان آنها وجود ندارد. ضریب همبستگی پیرسون، r نوعی اندازه گیری است که بیان کننده ی میزان و چگونگی قرار گرفتن نقاط به صورت خوشه هایی در طول یک خط مستقیم است.
ضریب همبستگی پیرسون (r)
همچنانکه در موارد بسیاری رخ می دهد، در مورد مثال ذکر شده دو متغیر با مقیاس های فاصله ای متفاوتی اندازه گیری شده بودند. این مسئله تصمیم گیری در باره ی چگونگی برتر بودن نمرات یک متغیر را در ارتباط با متغیر دیگر مشکل می سازد. آیا میزان 30 ساعت در هر هفته به عنوان زمان مطالعه برای کسب نمره ی 60 از 100 در یک امتحان مناسب است؟ برای فائق آمدن بر این مشکل نیاز است که نمرات استاندارد شوند که جهت انجام این کار نیاز است نمرات z در ارتباط با دو متغیر محاسبه شوند. (پانویس شود 18) همانطور که می دانیم نمرات استاندارد موقعیت یک نمره را نسبت به میانگین و بر حسب انحراف معیار آن می سنجند. با محاسبه ی نمرات استاندارد می توان موقعیت نسبی هر نمره را در توزیع متغیر بدست آورد. میانگین متغیر زمان مطالعه برابر با 29 و انحراف معیار آن 11.42 است که با x نمایش داده می شود. همچنین میانگین متغیر عملکرد آزمون 56 و انحراف معیار آن 11.80 است که با y نشان داده می شود. نمره ی استاندار z برای هر متغیر در جدول زیر آمده است.
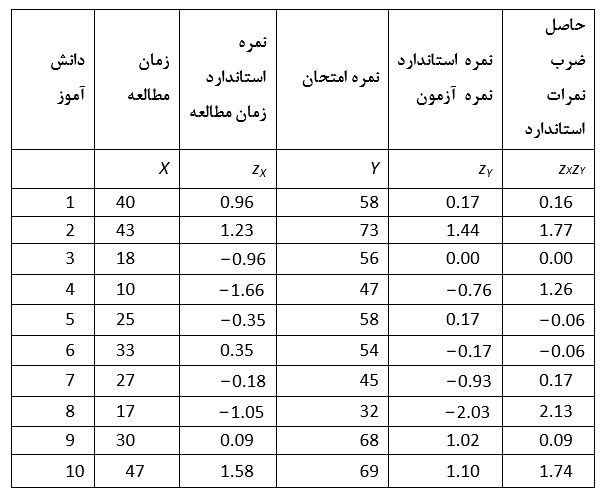
اکنون در ارتباط با هر کدام از شرکت کننده ها متوجه می شویم که آیا موقعیتی که یک متغیر در ارتباط با توزیع خودش دارد متغیر دیگر نیز مشابه آن است یا نه. با مشاهده ی جدول بالا متوجه می شویم که برای هر شرکت کننده نمره ی استاندارد z به سمت کوچکتر شدن میل می کند. اندازه های یکسان نمرات استاندارد z نشان از نوعی همبستگی دارند و علامت های یکسان (هر دو مثبت یا هر دو منفی) دلیل مثبت بودن این همبستگی است. (اگر مقادیر مشابه ولی علامت ها متفاوت باشد نیز یک همبستگی منفی را به دنبال دارد.) چگونه می توان این شباهت ریاضی را اذعان نمود؟ یک راه این است که برای هر کدام از شرکت کنندگان نمره ی استاندارد z را در دو متغیر ضرب کنیم. زمانی که همبستگی وجود داشته باشد اندازه ی نمرات استاندارد z نزدیک به هم خواهد بود و در نهایت اعداد بزرگ در هم ضرب شده و به همین ترتیب اعداد کوچک هم در هم ضرب می شوند. یک همبستگی مثبت اغلب ضرب کردن نمرات استاندارد z با علامت مشابه را در کارنامه ی خود داشته است (که در اصل یکسان بودن علامت ها مد نظر است و این علامت ممکن است برای هر دو عدد مثبت و یا منفی باشد)، به صورتیکه حاصلضربهایی که تولید می شوند

همبستگی مثبت توسط r بزرگتر از صفر و منفی نشان داده می شود و همبستگی منفی با کوچکتر از صفر. میزان قوی بودن همبستگی بدین صورت که چه میزان مقدار r به 1 (و یا در حالت منفی به -1) نزدیک باشد سنجیده می شود. در مورد مثال ذکر شده r = 0.72، که چون بیشتر به 1 نزدیک است تا 0 به عنوان همبستگی بزرگی تلقی می شود. در ادامه خواهیم دید که آیا معنی دار است یا نه.
اهمیت بررسی r هم از جهت بررسی میزان و هم علامت آن است، به گونه ای که می توان فرمولی ایجاد کرد که با استفاده از آن با داشتن نمرات یک متغیر، نمرات دیگر متغیر را پیش بینی کرد. اگر نمرات استاندارد z مربوط به دو متغیر در یک نمودار پراکنش رسم شوند مشاهده خواهیم کرد که r در واقع همان شیب خط رگرسیونی خواهد بود (خط مستقیمی که بهترین نماینده برای رابطه ی خطی متغیرها است که در اصطلاح به آن “بهترین خط برازش شده” گفته می شود) که در حقیقت خطی است که فرض می کند که نمرات استاندارد z با خطای تصادفی در کنار هم قرار گرفته اند. اگر فرمول بهترین خط برازش شده را روی نمودار بکشیم خواهیم داشت
zY = rzX. بنابراین با هر نمره ی استاندارد z در ارتباط با یک متغیر این فرمول را می توان به کار برد، اکنون در صورتیکه نمرات در طول یک خط مستقیم قرار گیرند با دانستن r می توان نمرات استاندارد z مربوط به دیگر متغیر را پیش بینی کرد. در حالت کلی چنین روشی بسیار مناسب است اما مشکل این روش این است که نمرات استاندارد z چیزی نیستند که ما خواهان آنها هستیم! و نیاز است که به نمرات اصلی دست یابیم.
روشی ساده جهت محاسبه ی r
برای محاسبه ی r نیازی به تولید نمرات استاندارد z نیست و جهت محاسبه ی آن از فرمولی مشابه روش قبل استفاده شده با این تفاوت که در آن نمرات اصلی کار برده می شوند


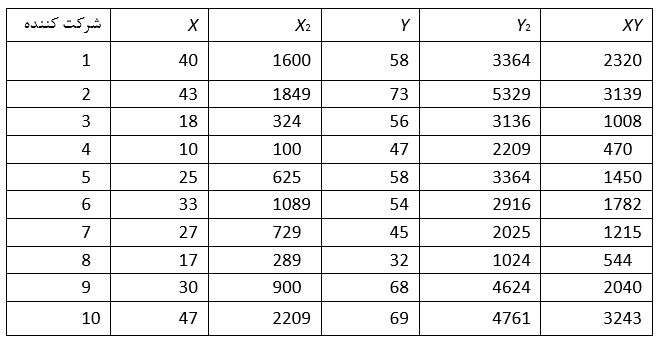
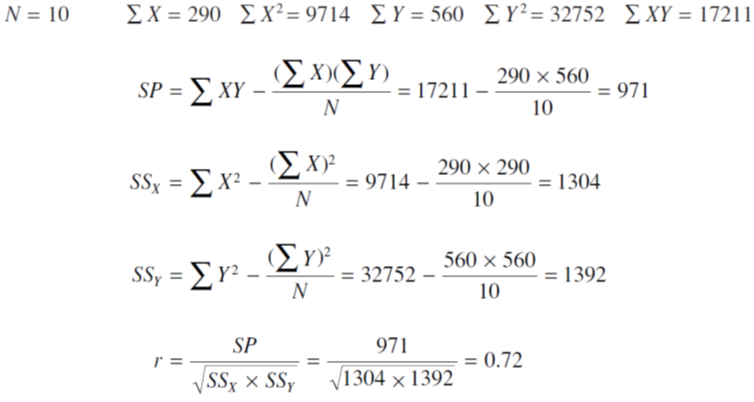
اکنون بايد احتمال يافتن تصادفي يك r به بزرگي و يا حتي بزرگتر بودن از 0.72 را بيابيم و بررسي كنيم كه آيا در حقيقت اين همبستگي مي تواند معني دار باشد و يا خير.
توزیع r
زمانی که هیچگونه ارتباطی میان دو متغیر وجود نداشته باشد انتظار می رود که r برابر با صفر بدست آید. اما مانند همیشه اطراف این نقطه تغییرات تصادفی وجود دارد.
r
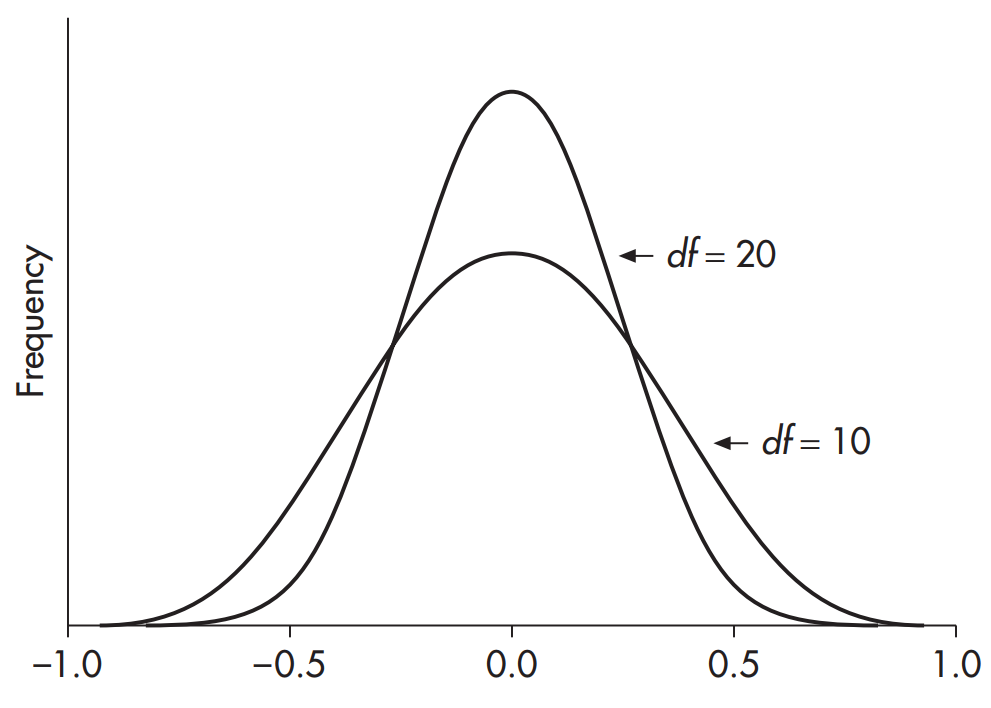
شکل 2-20- توزیع ضریب همبستگی پیرسون (r)
مقادیر r نسبت به صفر انحراف دارند اما در حالت کلی به صورت تصادفي در بازه ی +1 تا -1 تغییر می کنند. با توجه به این امر می توان فهمید که توزیع r تحت فرض صفر حول صفر متقارن است و دنباله های آن به سمت +1 و -1 منقطع می شوند. زماني كه تعداد آزمودني ها كم باشد توزيع نسبتاً يكنواخت و مسطح بوده و در صورتيكه تعداد زيادي آزمودني وجود داشته باشد تعداد بيشتري از خوشه ها حول ميانگين رخ خواهد داد. زماني كه تعداد بيشتري از آزمودني ها وجود داشته باشند اثر جداگانه ي هر كدام از آزمودني ها روي همبستگي كمتر شده و شانس اينكه r از صفر فاصله داشته باشد كمتر مي شود. زماني كه توزيع r را جهت مقايسه با مقدار محاسبه شده مان به كار مي گيريم بايد توجه داشته باشيم آنچه در اين رابطه مهم است درجه آزادي مي باشد و نه تعداد واقعي كل آزمودني ها. در مورد r درجه ي آزادي به دليلي كه در ادامه خواهد آمد برابر با N-2 است (نه 1N-). r در حقيقت شيب بهترين رگرسيون خطي برازش شده در ارتباط با نمرات z است. از آنجا كه جهت رسم يك خط مستقيم مشخص نياز به حداقل دو نقطه داريم، بنابراين در يافتن اين خط دو درجه ي آزادي مصرف شده و از تعداد كل آزمودني ها كاسته مي شوند. (در ساير آزمونها به خاطر ميانگين نمونه فقط يك درجه ي آزادي مصرف مي شود.) توزيع r در نمودار 20.2 به نمايش درآمده است.
پيش بيني در مورد همبستگي ممكن است به صورت يك دنباله اي و يا دو دنباله اي صورت پذيرد. آزمون یک دنباله ای اطلاعاتی از مثبت و منفی بودن همبستگی نیز می دهد در حالیکه در مورد نوع دو دنباله ای آن صرفاً معنی دار بودن همبستگی را پیش بینی می کند. در تنظیمات سطح معنی داری نیز باید لحاظ شود. در مورد مثال ذکر شده ضریب همبستگی به صورت مثبت پیش بینی شد، بدین معنی که مادامی که سطح عملکرد آزمون بالا رود زمان مطالعه نیز افزایش می یابد، بنابراین با یک آزمون یک دنباله ای مواجه هستیم. 291با توجه به جدول r (جدول A.9 ضمیمه)، با در نظر گرفتن آزمون یک دنباله ای و p = 0.05 با 8 درجه آزادی خواهیم داشت r = 0.5494. از آنجاییکه مقدار محاسبه شده برابر با 0.72 و بزرگتر از مقدار جدول بدست آمده است بنابراین فرض صفر رد شده و ادعا می شود که همبستگی معنی داری میان متغیرها وجود دارد.
مترجمین: دکتر هدی کامرانی فر – حسن اسکندری نیا




