آمار به زبان ساده | آنالیز واریانس با یک عامل اندازه گیری شده مستقل
27 مهر 1400
دقیقه
پس از مطالعه فصل نهم آمار به زبان ساده – مقدمهای بر آنالیز واريانس, در این فصل به آنالیز واریانس با یک عامل اندازه گیری شده مستقل خواهیم پرداخت.

آخرین بهروزرسانی: 24 دی 1401
پس از مطالعه فصل نهم آمار به زبان ساده – مقدمهای بر آنالیز واریانس, در این فصل به آنالیز واریانس با یک عامل اندازه گیری شده مستقل خواهیم پرداخت.
آنالیز واریانس (ANOVA) با یک عامل اندازه گیری شده مستقل شبیه آزمون مستقل t است اما به ما امكان مقایسه بیش از دو سطح را می دهد. آنالیز واریانس داده را در یك طرح اندازهگیریهای مستقل تحلیل میكند و بنابراین عنوان های موضوعی متفاوتی را در هر حالت به كار میگیرد.
اگر بخواهیم كه فقط دو گروه، همانند كودكان 5 ساله را با كودكان 7 ساله در یك آزمون خواندن مقایسه كنیم میتوانیم از آزمون t، یا آنالیز واریانس استفاده كنیم. صرفنظر از نوع آزمونی كه به كار میبریم خروجی یكسانی خواهیم گرفت. لیكن اگر بخواهیم گروههای بیشتری را مقایسه كنیم مثلاً 5، 6 و هفت ساله، آنگاه باید آنالیز واریانس را به كار بگیریم. (این شكل از آنالیز واریانس، آنالیز واریانس با طرح كاملاً تصادفی نامیده میشود)
تحلیل تغییرپذیری در آنالیز واریانس با اندازه گیری های مستقل
در فصل پیش دیدیم كه تغییرپذیری نمرات بین سطوح از تفاوتهای سیستماتیك بین معادلات باضافه خطای تصادفی ناشی میشود. در طرح اندازهگیریهای مستقل عنوان های موضوعی متفاوتی بودند كه نمرات را برای سطوح مختلف مهیا میكردند بنابراین بخشی از واریانس میان سطوح نشان از تفاوتهای انفرادی بین آزمودنی ها خواهد بود. این یك خطای تصادفی است زیرا ما به صورت سیستماتیك آزمودنی ها را در طول سطوح تغییر نمیدهیم. خطای تصادفی دیگر را میتوان با اصطلاح خطای آزمایشی عنوان كرد زیرا ما علیرغم آنكه قصد داریم شرایط یكسانی برای آزمودنی ها مهیا كنیم، همیشه مقداری خطای تصادفی در هر آزمایش میگیریم.
واریانس بین گروهی میتواند به عنوان چیزی برخاسته از سه منبع دیده شود: تفاوتهای سیستماتیك بین سطوح، تفاوتهای جداگانه و خطای آزمایشی.
اگر به تغییرپذیری نمرات درون سطوح نظر كنیم تفاوتهای سیستماتیكی نخواهیم دید (اگر آزمایش را به درستی انجام داده باشیم) اما هنوز آزمودنی های متفاوتی درون یك سطح وجود دارد كه میتوانیم انتظار داشته باشیم كه تغییر پذیری آن ها ناشی از تفاوتهای فردی باشد. مجدداً از آنجائیكه همواره ما انتظار خطاهای تصادفی دیگری را داریم كه اصطلاح خطای آزمایشی را برای آنها عنوان كردیم، میتوان انتظار داشت كه آنان به صورت تصادفی در هر جای آزمایش اتفاق بیفتند.
از اینرو واریانس درون گروهی شامل دو جزء: تفاوتهای فردی و خطای آزمایشی است. بنابراین واریانس درون گروهی، واریانس خطا را كه نیازمندیم به ما میدهد همچنانکه این شاخص جدای از خطای سیستماتیک بین سطوح، مانند واریانس بین گروهی تحت تاثیر تغییر پذیری مشابهی قرار می گیرد. مقایسه میان واریانس بین گروهی با واریانس درون گروهی به ما نسبت واریانسی را میدهد كه میتوان آن را محاسبه كرده و آن را با توزیع F برای جستجوی تأثیر متغیر مستقلمان بر متغیر وابسته، مقایسه نمود میخواهیم F را كه نسبت زیر است تولید كنیم.

جدول خلاصه آنالیز واریانس
برای محاسبه F نیاز است كه اجزاء چندی از آنالیز واریانس را بسازیم. مانند مجموع مربعات، درجه آزادی، واریانسها و غیره. برای انجام این امر و نمایش شفافه محاسبات جدول خلاصه آنالیز واریانس را درست میكنیم.
این خلاصه منابع تغییرات را به عنوان ردیفهای جدول در نظر میگیرد. در آنالیز واریانس (ANOVA) با یک عامل اندازه گیری شده مستقل ما با واریانس درون گروهی و واریانس بین گروهی درگیر هستیم. همچنین برای محاسبه مجموع مربعات نیاز به كل تغییرپذیری دادهها نیازمندیم. ستونهای جدول به ترتیب مراحل میانی تولید واریانسهای لازم برای نسبت واریانس، در كنار محاسبه نهایی F و معناداربودن آن را به ما می دهند. برای محاسبه واریانس به مجموع مربعات و درجه آزادی نیاز داریم. در اصطلاح آنالیز از واریانس به عنوان میانگین مربعات یاد میكنیم (MS) این یك عنوان دیگر است که به صورت ساده تر بیان می شود. از آنجائیكه تقسیم مجموع مربعات بر درجه آزادی، میانگین مربعات را ایجاد میكند، به صورت توصیفی مناسب تر باشد.
معنادار بودن یا نبودن مقدار محاسبه شده F در جدول به دو شكل میتواند نشان داده شود. معین کردن احتمال مقدار F تحت فرض صفر داده شده، برای مثال 0145/0=P. در این حالت خواننده میتواند مشاهده كند كه آیا احتمال از سطح معنی داری انتخاب شده مثل 05/0=P، بزرگتر یا كوچكتر است. دوم احتمال میتواند در رابطه با سطح معنی داری داده شود. مثل 05/0P< تا روشن كند كه مقدار F در سطح 05/0=P معنادار بوده و 05/0P> تا دلالت كند كه در سطح معنی داری 05/0، معنادار نیست. من قاعده دوم را به كار میبرم.
برای آنالیز واریانس (ANOVA) با یک عامل اندازه گیری شده مستقل جدول خلاصه به روش زیر چیده میشود.
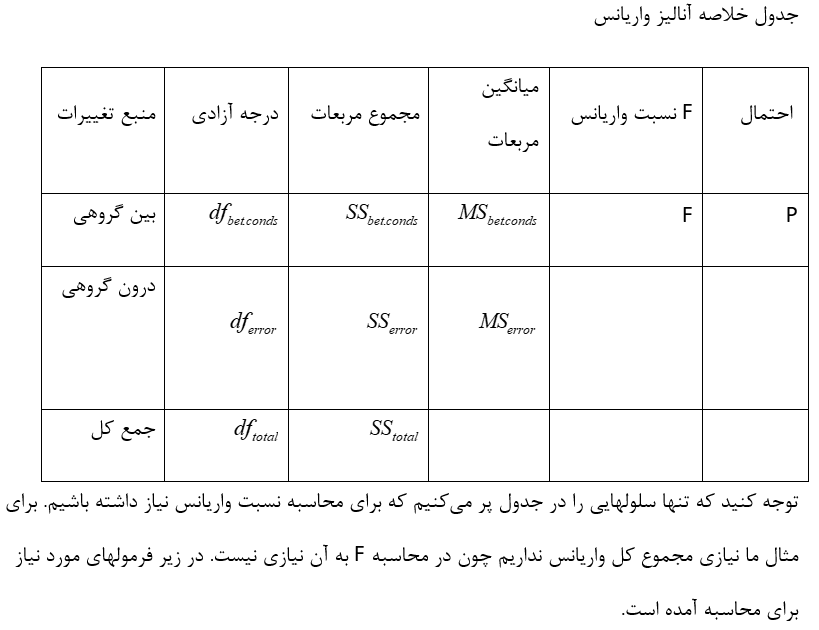
توجه كنید كه تنها سلول هایی را در جدول پر میكنیم كه برای محاسبه نسبت واریانس نیاز داشته باشیم. برای مثال ما نیازی مجموع كل واریانس نداریم چون در محاسبه F به آن نیازی نیست. در زیر فرمولهای مورد نیاز برای محاسبه آمده است.



یك مثال کاربردی
یك محقق به اثر راهنمایی در مسابقه كلمهسازی علاقمند بوده است. زمانی كه طول كشیده تا یك شركتكننده 5 كلمه 8 حرفی بسازد اندازه گرفته شده است. همان كلمات 5 گانه در سه سطح به كار برده شدهاند: حرف اول (در جایی كه حرف اول كلمه داده شده) آخرین حرف (جائیكه حرف آخر كلمه داده شده) و بدون حرف (جائیكه هیچ كمكی نشده است)، سی شركتكننده برگزیده شده و به صورت تصادفی در هر سطح 10 نفر اختصاص داده شدند. زمانی كه برای حل 5 كلمه استفاده شد محاسبه و ثبت گردید. نتایج در زیر نشان داده شدهاند. آیا اثری از نوع راهنمایی (متغیر مستقل) روی زمان حل مسئله (متغیر وابسته) وجود دارد؟



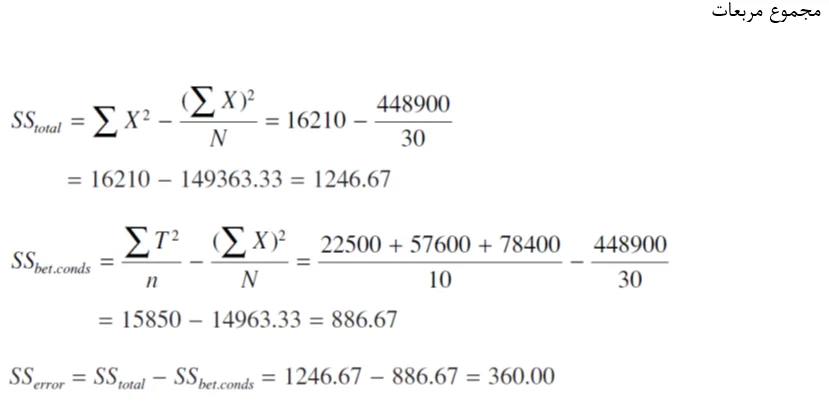

از جدول توزیع F (جدول A3 ضمیمه) درمی یابیم كه در 05/0=P 35/3=F(2,27) است. از آنجا كه مقدار ما یعنی 26/33 بزرگتر از مقدار جدول است فرض صفر را رد كرده و ادعا میكنیم كه زمان حل كلمهسازی از نوع راهنمایی داده شده تأثیر میپذیرد. توجه كنید كه نتیجه به شدت معنادار است بنابراین میتوانیم سطح معنی داری محافظهكارانهتری را بپذیریم. در 01/0=P F(2,27)=5.49 است بنابراین یافتههای ما برای مقادیر 01/0P< هم همچنان معنادار هستند.
این واقعیت كه یك اثر معنادار یافتهایم به ما نمیگوید كه كدام سطح به صورت معناداری متفاوت است بهرحال میتوانیم این را با نگاهكردن به میانگینها بدست بیاوریم. در فصلهای بعدی قادر خوهیم بود كه بسیار دقیقتر به بررسی این مورد بپردازیم. اگرچه آزمون F ما تفاوتهای معناداری بین حالات یافته است اما علت آن را برای ما بیان نمیكند.
ما امیدواریم كه آزمایش آنقدر خوب كنترلشده باشد كه تفاوتها تنها ناشی از نوع راهنمایی باشند اما اگر محقق هر فاكتور اختلاط گری را به صورت غیرعمدی وارد كرده باشد این مسئله میتواند تفاوتهای سیستماتیكی را تولید كند كه در آنالیز واریانس آمده باشند.
جدول خلاصه آنالیز واریانس ANOVA
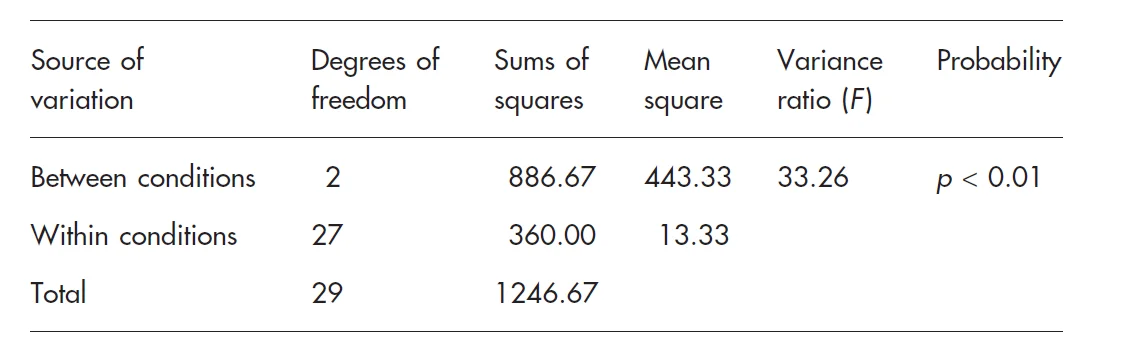
جدول بالا بوضوح تجزیه و تحلیل را خلاصه میكند. همچنین به ما اجازه میدهد كه محاسباتمان را بررسی كنیم یعنی آیا درجه آزادی و مجموع مربعها به جمع كل افزوده شدهاند؟ مجموع مربعات شما نباید هیچوقت منفی باشد زیرا جمع مربعات باید مثبت باشد (نمیتواند منفی باشد) اگر شما عدد منفی بدست آوردهاید محاسبات را بررسی كنید قطعاً خطایی وجود دارد.
ردكردن فرض صفر
وقتیكه كه در یك آنالیز واریانس فرض صفر را رد میكنیم همانند آنچه در مثال بالا انجام دادهایم فقط نتیجه میگیریم كه تفاوتهای سیستماتیكی بین حالات وجود دارد اما نه اینكه آنها در كدام بخش هستند. در مورد سه حالتی چهار جایگزین برای فرض صفر موجود است: 1- هر سه سطح به صورت معناداری متفاوتند و نمونههای آنها از جمعیت هایی با توزیع های متفاوت میآیند. 2- سطح اول به صورت معناداری با حالات دوم و سوم متفاوت است ولی حالات دوم و سوم به صورت معناداری متفاوت نیستند.
نمونه سطح اول از توزیع متفاوتی از نمونههای حالات دوم و سوم میآید. 3- سطح دوم به صورت معناداری متفاوت از سطوح اول و سوم است اما سطوح اول و سوم به صورت معنادار متفاوت نیستند. یعنی نمونه سطح دوم از توزیع متفاوتی نسبت به نمونههای اول و سوم میآید. 4- سطح سوم تفاوت معناداری نسبت به سطح اول و دوم داشته اما سطح دوم و سوم تفاوت معناداری با هم ندارند. یعنی نمونه سطح سوم از یك توزیع متفاوتی نسبت به نمونههای سطح اول و دوم میآید.
با سطوح بیشتر، تعداد فرضهای جایگزین افزایش مییابد. یك مقدار F معنادار به آسانی دلالت بر آن دارد كه فرض صفر بسیار غیرمحتمل است و بنابراین ما آن را رد میكنیم. ما برای اینكه تصمیم بگیریم كه كدامیك از فرضهای جایگزین را بپذیریم نیازمند آن هستیم كه آزمایشهای بیشتری را انجام دهیم.

نمونههای با اندازه متفاوت معمولاً زمانی رخ میدهد كه شما برای تعداد متساوی در هر سطح برنامهریزی كردهاید ولی به دلایلی یك آزمودنی قادر به دادن یك نمره نیست. در مثال كلمهسازی، ممكن است فردی را بیابیم كه نتواند هر چه قدر هم كه به او زمان بدهیم كلمهای بسازد. یك راه حل آن است كه یك مشاركتكننده را با دیگری جایگزین كنیم. بهرحال تغییر در فرمول آنقدر كوچك است كه نمونههای با اندازه متفاوت واقعاً یك مشكل نیست (تا زمانیكه فرض مساویبودن واریانس جمعیتها باقی ماند.)
یك مثال کاربردی
به عنوان مثالی از محاسبات با اندازه نمونه های نامساوی باید داده های به كار رفته در آزمون مستقل t در فصل 8 را به كار ببرم. این مثال اثر قرصهای خوابآور را روی 6 مرد و 8 زن مقایسه میكرد. نمرات مردان (سطح اول) 4، 6، 5، 4، 5 و 6 و نمرات زنان (سطح دوم) 3، 8، 7، 6، 7، 6، 7 و 6 ساعت خواب اضافی برای آنان بودند.


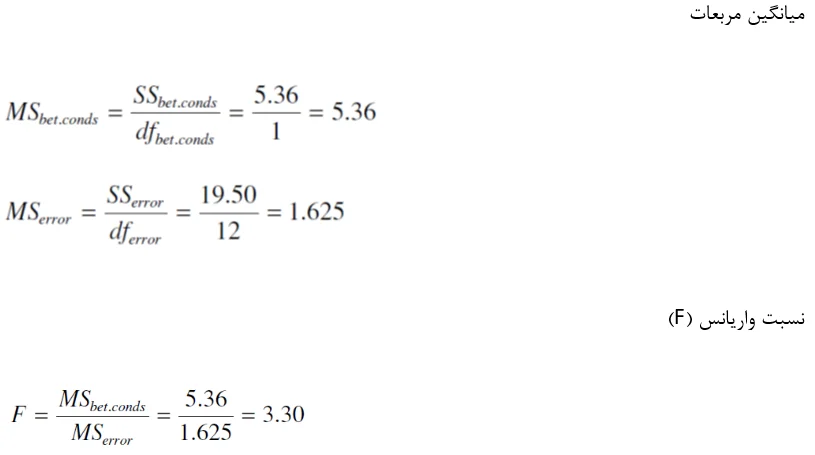
جدول خلاصه آنالیز واریانس
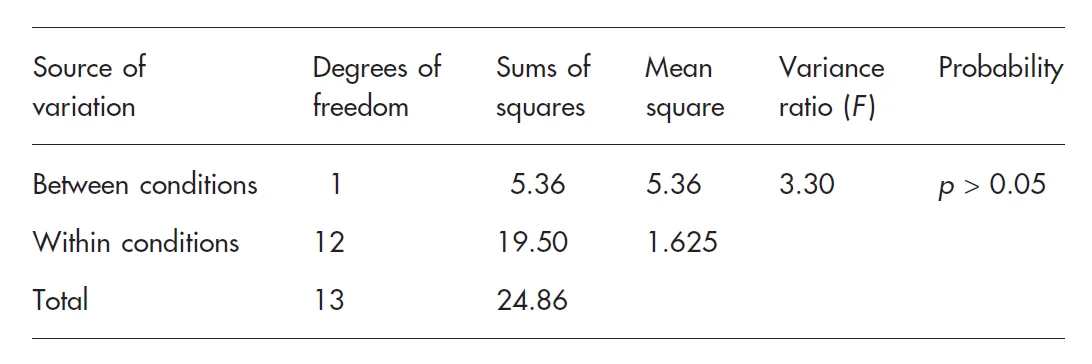
از جدول توزیع F (جدول A.3 در پیوست) در میابیم که F(1,12)=4/75 در p=0/05. چون مقدار محاسبه شده F برابر 30/3 کمتر از مقدار جدول است فرض صفر با این سطح معنی داری رد نمی شود.
رابطه توزیع F با t
مثال بخش بالا به ما اجازه می دهد كه یك آنالیز واریانس را با یك آزمون t مستقل در روی همان دو نمونه مقایسه كنیم. اگر برگردید و به محاسبات t نظری بیاندازید میتوانید مشابهتهایی بین محاسبات ببینید برای مثال به در پائین محاسبات t توجه كنید. اگر بیشتر جستجو كنیم میتوانیم ببینیم كه دو فرمول چگونه بهم مرتبط هستند. مقدار محاسبه شده F یعنی 30/3 مسلماً مربع مقدار محاسبه شده 82/1=t است. به صورت مشابه مقادیر جدول F و t به همان ترتیب مرتبط هستند و ما همان خروجی را از دادهها، در هر كدام از آزمونها که روی آنها انجام دهیم خواهیم داشت.
جزئیات محاسبه اندازه آنالیز واریانس با اندازه گیری های مستقل با استفاده از بسته نرمافزاری SPSS را میتوانید در فصل 10 كتاب هینتن و دیگران (2004) بیابید.
مترجمین: دکتر هدی کامرانی فر – حسن اسکندری نیا




