آنالیز واریانس یک عاملی برای داده های رتبه ای – بخش 1
22 آذر 1400
دقیقه
زمانیکه داده های مورد تحلیل دارای مقیاسی فاصله ای نباشند و یا فرضیات آنالیز واریانس برقرار نباشند لاجرم می بایست از آزمون های ناپارامتری استفاده شود. در مورد طرحهایی با یک عامل زمانیکه دو نمونه داشته باشیم، چنانچه نمونه ها مستقل باشند از آزمون کروسیکال – والیس (Kruskal–Wallis ) و در صورت وابسته بودن آنها از آزمون فریدمن (Friedman) استفاده می شود. این آزمونها معادل های ناپارامتری آنالیز واریانس یک عاملی با اندازه گیری های مستقل و آنالیز واریانس یک عاملی با اندازه گیری های مکرر هستند.

آخرین بهروزرسانی: 24 دی 1401
در مقاله قبلی به بخش دوم آزمون رتبه ای علامت دار ويلكاكسون در نمونه های وابسته پرداختیم. در این فصل به آموزش آنالیز واریانس یک عاملی برای داده های رتبه ای در ادامه سری مقالات آموزشی آمار به زبان ساده می پردازیم.
زمانیکه داده های مورد تحلیل دارای مقیاسی فاصله ای نباشند و یا فرضیات آنالیز واریانس برقرار نباشند لاجرم می بایست از آزمون های ناپارامتری استفاده شود. در مورد طرح هایی با یک عامل زمانیکه دو نمونه داشته باشیم، چنانچه نمونه ها مستقل باشند از آزمون کروسیکال – والیس (Kruskal–Wallis) و در صورت وابسته بودن آنها از آزمون فریدمن (Friedman) استفاده می شود. این آزمونها معادل های ناپارامتری آنالیز واریانس یک عاملی با اندازه گیری های مستقل و آنالیز واریانس یک عاملی با اندازه گیری های مکرر هستند.
آزمون کروسیکال-والیس (اندازه گیری های مستقل)
آزمون کروسیکال-والیس آزمونی مشابه آنالیز واریانس رتبه ها است. از این آزمون زمانی که فرضیات آنالیز واریانس پارامتری برقرار نیست استفاده می شود. نمونه ای از کاربرد چنین داده هایی در ادامه نشان داده می شود. محققی علاقه مند به بررسی میزان جذابیت و افراد منتخب برای تعدادی شغل است. همچنین علاوه بر آزمون کردن میزان جذابیت در افراد مؤنث، تعدادی از آزمایشات روی مردان صورت گرفت.
اکنون این سؤال مطرح است که آیا انواع مختلفی از موهای صورت تأثیری در قضاوت صورت گرفته ایجاد می کند. یکی از کارمندان مامور زن در یک شرکت بزرگ موافق بود که به چهره ی مردان بر حسب میزان جذابیت امتیازی در مقیاس 0 تا 50 داده شود که مقدار بالای امتیاز نمایانگر میزان بالای جذابیت است.
در خارج از یک استخر بزرگ پنج مرد با ریش، پنج مرد با سبیل و پنج مرد کاملاً اصلاح شده و بدون ریش و سبیل به صورت تصادفی انتخاب شدند. (برای گرفتن این عکس ها نوعی یکسان سازی در مواردی چون سن، مدل موها و مرتب بودن صورت گرفته بود.) آیا با آزمون کردن داده های زیر می توان قضاوتی در مورد اثر موی صورت روی میزان جذابیت انجام داد؟
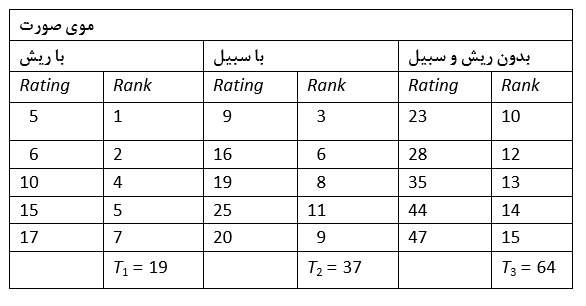
اندازه گیری های مستقلی در ارتباط با موی صورت وجود دارد بنابراین صرف نظر از سطحی خاص به نمرات در مجموعه ی داده ها رتبه داده می شود. رتبه ها در جدول بالا نشان داده شده اند. در صورتیکه تفاوتی میان سطوح مختلف وجود نداشته باشد انتظار می رود که رتبه ها به صورت یکنواختی میان نمرات پراکنده شده باشند.
اما چنانچه اثر معنی داری روی متغیر وابسته وجود داشته باشد انتظار داریم که تغییرات منظمی میان سطوح مختلف وجود داشته باشد، به عنوان مثال همه ی نمرات با رتبه های بالا در یک سطح قرار گیرند. بنابراین نیاز است جهت پیدا کردن راهی برای بررسی وجود خوشه بندی در رتبه های مشابه درون سطوحی خاص راهی یافته شود.


فرمول بدست آمده نشان می دهد که در ارتباط با مجموعه ای از داده ها MStotal برای یک مقدار ثابت N، یکسان خواهد بود. در این بخش متوجه خواهید شد چرا به جای F از H استفاده می شود. MStotal شرایطی را مهیا می سازد تا صرف نظر از اثر متغیر مستقل با داشتن N رتبه مقداری ثابت را برای میانگین واریانس بدست آوریم.
چنانچه تغییر پذیری بین سطوح را در مقابل مقدار ثابت بدست آمده محاسبه کنیم خواهیم دید که در حقیقت این مقدار بزرگتر از میزان بدست آمده برای تغییر پذیری بین سطوح است. به عنوان مثال، با مقدار N=15 مقدار MStotal برابر با 20 خواهد بود (البته زمانی که رتبه های گره خورده وجود نداشته باشد).
با استفاده از فرمول معمولی مجموع مربعات خواهیم داشت:


توزیع H
چرا زمانی که با رتبه ها سروکار داریم به جای F باید توزیع H را بیابیم؟ برای این سؤال چندین دلیل وجود دارد. همچنانکه در بخش قبل ذکر شد برای یک مقدار مشخص N، MStotal مقداری ثابت است. در مورد مثال بیان شده با N=15، مقدار MStotal صرف نظر از تعداد سطوح و میزان تغییرپذیری میان آنها برابر با 20 خواهد بود. بنابراین می توانیم از MStotal به عنوان محکی جهت مقایسه ی تغییرپذیری واقعی رتبه ها میان سطوح استفاده کنیم.
در صورتیکه هیچگونه تغییر پذیری میان سطوح وجود نداشته باشد مقدار SSbet.conds به دلیل مساوی بودن جمع کل رتبه های درون هر سطح، برابر با صفر خواهد بود و چنانچه میزان تغییر پذیری بین سطوح زیاد باشد در نتیجه SSbet.conds به دلیل قرار گرفتن رتبه های مشابه در سطحی خاصل و ایجاد نوعی خوشه بندی، بزرگ خواهد شد.
اما چگونه این بزرگی ایجاد می شود؟ به این دلیل آن را (مترجم: SSbet.conds) با MStotal مقایسه می کنیم. در مورد مثال ذکر شده زمانی که به صورت جداگانه مقادیر را محاسبه کنیم خواهیم داشت: SSbet.conds = 205.2 و MStotal = 20، که SSbet.conds ،10 برابر بزرگتر از MStotal است و دلالت بر عدم تصادفی بودن تغییر پذیری بین سطوح داشته و نشان می دهد که موی صورت روی قضاوت در مورد جذابیت تأثیر می گذارد. اکنون نیاز است که توزیع H را تحت فرض صفر جهت بررسی معنی داری آن بیابیم.

رتبه های گره خورده:
چنانچه رتبه های گره خورده وجود داشته باشد می بایست برای محاسبه ی SSbet.conds و MStotal از همان فرمول های اصلی استفاده شود. زمانی که با وجود رتبه های گره خورده از چنین فرمول هایی برای محاسبه H استفاده شود مقدار H ممکن است از مقدار واقعی آن کوچکتر شده و منجر به از بین رفتن معنی داری شود.

به هر حال این مسئله تنها زمانی که آماره محاسبه شده نزدیک به معنی داری باشد اتفاق می افتد و تنها در مواردی که ممکن است معنی داری را از دست بدهیم باید توجه به این امر داشته و حساسیت لازم را به خرج دهیم. در بیشتر موارد بدون اینکه نگران رتبه های گره خورده باشیم می توان با استفاده از فرمول های ساده تر به محاسبه ی آماره ی H پرداخت. البته تا زمانی که رتبه های گره خورده خیلی زیاد نباشند.
مترجمین: دکتر هدی کامرانی فر – حسن اسکندری نیا




