آمار به زبان ساده – آمار توصیفی
20 مرداد 1400
دقیقه
دلیل اصلی محاسبات آماری توصیف و خلاصه کردن مجموعهای از دادههاست. انبوهی از اعداد معمولاً خیلی آگاهی بخش نیست بدین دلیل نیازمندیم که راهی برای انتزاع دادههای کلیدی بیابیم تا به ما اجازه دهد دادهها را به شکلی واضح و قابل درک ارائه کنیم. در این فصل به یک مثال که شامل مجموعهای از دادههاست نظری افکنده و بهترین راه توصیف (آمار توصیفی) و خلاصه کردن آن را ملاحظه میکنیم.

آخرین بهروزرسانی: 24 دی 1401
دلیل اصلی محاسبات آماری توصیف و خلاصه کردن مجموعهای از دادههاست. انبوهی از اعداد معمولاً خیلی آگاهی بخش نیست بدین دلیل نیازمندیم که راهی برای انتزاع دادههای کلیدی بیابیم تا به ما اجازه دهد دادهها را به شکلی واضح و قابل درک ارائه کنیم. در این فصل به یک مثال که شامل مجموعهای از دادههاست نظری افکنده و بهترین راه توصیف (آمار توصیفی) و خلاصه کردن آن را ملاحظه میکنیم.
آمار به زبان ساده – آمار توصیفی
یکصد دانشجو در آزمونی شرکت میکنند. پس از آزمون، اوراق اصلاح شده و نمره یکصد نفر مشخص میشود. نمرات را به شما میدهند و از شما خواسته میشود آنها را برای ارائه به کمیتهای که کارآیی امتحانات را زیرنظر دارد آماده کنید. یکصد نمره داده شده به شما به شرح زیر است:
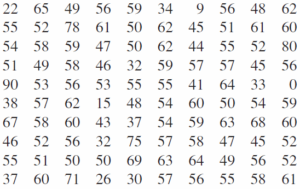
خوشبختانه به شما گفته میشود که نوع سوالات کمیته ممکن است مانند اینها باشد:
- آیا میتوانید نتیجه آزمون را بیان کنید؟
- آیا میتوانید شرح خلاصهای از نتیجه آزمون بدهید؟
- نمره میانگین چند است؟
- پراکندگی نمرات به چه صورت است؟
- بیشترین و کمترین نمرات کدامند؟
نتایج امسال در قیاس با نتیجه امتحان سال گذشته چگونه است؟
اکنون شما نشستهاید و به دادهها مینگیرد پاسخ به این سئوالات از دادههای خام یعنی دادههایی که هیچگونه محاسبات آماری روی آنها صورت نگرفته است واضح نیست. باید کاری انجام دهیم تا آنها را روشنتر کنیم. اولین کاری که میتوان انجام داد آن است که دادهها را از کوچک به بزرگ مرتب کنیم.
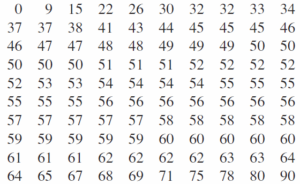
با این مرتبسازی بعضی چیزها آشکارتر میشود: اکنون بوضوح میتوانیم کمترین و بیشترین نمره را با بقیه نمرات که بین 0 تا 90 هستند ببینیم .
چیز دیگری که میتوانیم برای بهبود کار خود انجام دهیم جمع زدن افرادی است که نمره یکسان گرفتهاند. تعداد تکرار هر نمره را میشماریم. برای مثال 5 نفر نمره 52 و فقط یک نفر نمره 69 گرفته است. وقتی این کار را انجام دادیم متوجه میشویم فراوانترین نمره 56 با 7 مورد است. نباید فراموش کنیم نمراتی هم هستند که هیچکس آنها را نگرفته است: مثلاً کسی نمره 8 یا 35 بدست نیامده است، بنابراین تعداد تکرار این نمرات صفر است.
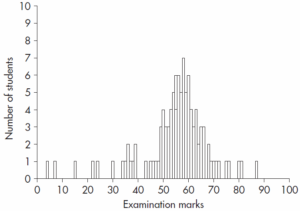
میتوانیم این اطلاعات را با تبدیل آنها به هیستوگرام، که در آن هر نمره به شکل یک میله عمودی نمایش داده میشود به صورت گرافیکی عرضه کنیم. در هیستوگرامی که در شکل 2.1 نشان داده شد، تمام نمرات متحمل را که یک دانشجو میتواند بگیرد از صفر تا صد فهرست میکنیم و بالای هر نمره میلهای به طول متناسب با تعداد تکرار آن رسم میکنیم. برای نمره 55 میلهای به طول 6 (زیرا 6 دانشجو نمره 55 گرفتهاند) و برای نمره 64 میلهای به طول 2 رسم میکنیم. این کار یک نمایش تصویری واضح از نمرات به ما عرضه میکند.
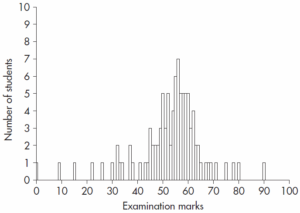
این هیستوگرام «توزیع فراوانی» نامیده میشود زیرا از طریق آن میتوانیم ببینیم که نمرات افراد چگونه در طول نمرات ممکن توزیع شدهاند. توزیع فراوانی در تحلیلهای آماری بسیار مهم است زیرا نمایشی پایهای از اطلاعات مهیا میکنند. توزیع فراوانی، یک نمودار آگاهی بخش واضح است زیرا الگویی از نمرات بدست آمده، یعنی توزیع آنها در میان مقادیر ممکن را نشان میدهد. ممکن است مایل باشیم توزیع فراوانی را بعنوان نمایشی تصویری از نمرات به کمیته عرضه کنیم اما از عهده خلاصه کردن دادهها بر نمیآید.
معیار گرایش به مرکز
آیا نمرهای وجود دارد که به تنهایی بهترین نشانگر همه نمرات باشد؟ آیا میتوانیم یک نمره نوعی که خلاصه همه یافتهها باشد به کمیته عرضه کنیم؟ معقولترین نمره برای استفاده در این مورد نمره مرکزی یا میانه نمرات است. در اصطلاح علوم آماری ما در حال تلاش برای یافتن معیار گرایش به مرکز هستیم. سوالی پیش روی ما این است که نقطه مرکزی در توزیع فراوانی ما چیست؟
یک پاسخ ساده، برگزیدن شایعترین نمره یعنی بلندترین میله هیستوگرام است. این قلم آماری را مد یا نما میگویند. همچنانکه در تصویر 2.1 میبینید طولانی ترین میله، نمره 56 است که هفت نفر آن را در آزمون بدست آوردهاند و نمره معقولی برای تخمین نمره مرکزی به نظر میآید. اما مد اغلب بدلایل چندی بعنوان معیار گرایش به مرکز به کار برده نمیشود.
اول: اگر دو نمره باهم بیشترین تعداد را در بین نمرات داشته باشند چه باید کرد؟ دوم: اوقاتی هست که مد به روشنی نمایانگر نمره مرکزی نیست. تصور کنید 10 دانشجوی ضعیف داشته باشیم که همگی در آزمون نمره صفر گرفته باشند درحالیکه بقیه همان نمراتی را که در تصویر 2.1 آمده است بدست آمده باشند. با وجود آنکه دسته ای از نمرات در اطراف 50 وجود دارد اما مد ما صفر خواهد بود. در این صورت مد سنجش ضعیفی برای گرایش به مرکز خواهد بود.
معیار دیگر گرایش به مرکز که اغلب بیشتر از مد مورد استفاده قرار میگیرد میانه است. وقتی که لیست را از کمترین به بیشترین نمره مرتب کنیم نمرهای که درست در وسط فهرست قرار میگیرد میانه است. مثلاً اگر 9 دانشجو در امتحان شرکت کرده بودند، پنجمین نمره در فهرست میانه میبود. اما بهرحال اکنون ما یکصد دانشجو داریم، عدد ما زوج است و تک نمرهای در وسط وجود ندارد.
وسط نمرات، بین نمرات پنجاهم و پنجاه و یکم خواهد بود. در مثال ما نمره پنجاهم و پنجاه و یکم هر دو 55 است. بنابراین میانه ما 55 خواهد بود. (اگر این دو نمره متفاوت بودند میانه وسط آن دو میبود یعنی دو نمره را با هم جمع کرده و بعد آنرا بر دو تقسیم مینمودیم تا مقدار میانه را بدست آوریم).
میانه از آنجائیکه نمره را از وسط توزیع دادهها بر میدارد، معیار خوبی برای گرایش به مرکز است. ضعف آن البته اگر ضعف محسوب شود آن است که، همانند مد، از همه اطلاعات داده شده بوسیله نمرات استفاده نمیکند. خیلی ساده میانه فهرست نمرات ما را به دو بخش مساوی تقسیم میکند. نمرات قبل و بعد میانه به ترتیب ممکن است هر نمرهای باشند.
اگر به کسی نمره 9 در آزمون داده شده باشد ولی نمره واقعی او 29 یا 39 باشد، تصحیح این نمره میانه را که نمره 55 است تغییر نخواهد داد زیرا او هنوز هم نمره وسط در فهرست است. میانه حتی اگر نمرهای تغییر کند همچنان همان باقی خواهد ماند (البته تا زمانیکه نمرهای زیر میانه به نمرهای در بخش بالای میانه یا برعکس تغییر نکند). میانه تنها بازگو کننده نمره میانی و نه همه نمرات می باشد.
با وجود آنکه، ممکن است میانه را از آن جهت که نقطه وسط نتایج و نه بیشترین تعداد تکرار را پیدا میکند، بعنوان یک گزینه بهتر از مد برای مقدار وسط مورد ملاحظه قرار دهیم، معیار سومی برای گرایش به مرکز وجود دارد که غالبا بیشتر از هر دوی آنها به کار برده میشود و آن میانگین است.
برای نمایش محاسبه میانگین از علائم خاصی استفاده میشود. حرف یونانی µ (مو) برای میانگین، حرف یونانی (سیگما) برای مجموع (یا افزودن) و حرف X برای نمایش یک نمره (که در مثال ما نمره آزمون است) و حرف N را برای تعداد نمرات به کار میبریم. نماد ∑ x یعنی همه نمرات را با هم جمع کنید. میانگین یا جمع همه نمرات تقسیم بر N تعداد آنهاست:
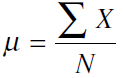
وقتیکه از معدل و متوسط گرفتن سخن میگوئیم معمولاً منظورمان میانگین است. (گرچه کلمه متوسط اغلب بسیار آزادانهتر از کلمه میانگین که تعریف آماری خاص خودش را دارد به کار میرود). برای محاسبه میانگین، همه نمرات آزمون را با هم جمع کرده که به عدد 5262 میرسیم و سپس آن را بر تعداد نمرات یعنی 100 تقسیم نموده، که نمره 62.52 را به ما میدهد.
یک راه برای اندیشیدن درباره میانگین مقایسه آن با بازی الاکلنگ است، تصور کنید محور افقی توزیع فراوانی ما یک تیر چوبی باشد که از صفر تا صد درازا داشته باشد. هرکدام از نمرات را دانشجویی فرض میکنیم بر روی تیر چوبی در آن نقطه نشسته است. (بنابراین روی شماره 56 تیر چوبی هفت دانشجو نشستهاند).
پایه الاکلنگ را در کدام نقطه باید قرار داد تا به خوبی تراز شود؟ پاسخ نقطه میانگین است. میتوان دید که میانگین امتیازات دو طرف خود را تراز میکند و در واقع میانگین مرکز ثقل است. هر تغییری در نمرات (در مثال ما دانشجویی را روی تیرچوبی جابجا کردن) موجب تغییر میانگین خواهد شد (الاکلنگ از حالت تراز خارج شده مگر آنکه جای پایه را تغییر دهیم تا دوباره تراز شود). بنابراین میانگین همانگونه که در بالا دیدیم یک قلم آماری است که برخلاف میانه، به همه نمرات حساس است.
نکته دیگری درباره میانگین که از مقایسه آن با الاکلنگ میتوانیم دریابیم آن است که: میانگین به مقادیر بسیار بزرگ، بسیار حساس است. یک نمره خیلی بالا یا خیلی پائین، تأثیر بزرگتری از یک نمره میانی، در موقعیت قرار گرفتن پایه الاکلنگ دارد. اگر روی یک الاکلنگ افرادی نشسته باشند و حالت آن تراز باشد، اگر فردی را در انتهای یک طرف بنشانیم طرف دیگر خیلی سریعتر بالا میرود تا آنکه او را در میانه الاکلنگ بنشانیم. بنابراین موقعیت میانگین مثل پایه الاکلنگ، با تعداد نمرات و همچنین، فاصله آنها از پایه مشخص میشود.
مقایسه معیارهای گرایش به مرکز
در مثال مطرح شده، سه معیار برای گرایش به مرکز داریم: مد با مقدار 56، میانه با مقدار 55 و میانگین با مقدار 52.62 . حال کدامیک را باید برگزینیم؟ پاسخ آن است که هرکدام را که بخواهیم، خیلی ساده، مقداری را انتخاب میکنیم که بهتر مقدار وسط را در توزیع، برای قصدی که داریم، نشان دهد. معمولاً این انتخاب، برگزیدن میانگین است چون همه نمرات در تعیین آن موثرند. اما اوقاتی هم وجود دارد که مد یا میانه را انتخاب میکنیم.
مد سریع است یکبار که توزیع فراوانی را درست کردیم خیلی راحت تعیین میشود. بنابراین میتوان آن را به عنوان یک معیار تقریبی و آماده، به کار برد، بدون اینکه منتظر محاسبات بیشتر باشیم. همچنین، میانه و میانگین را در مورد انواعی از دادهها نمیتوان به کار برد. برای مثال اگر برنامهای برای مسافرت گروهی با دوستان ترتیب داده و جاهایی را برای دیدن پیشنهاد کنیم. به احتمال زیاد مکانی را که بیشتر افراد ترجیح میدهند انتخاب خواهیم کرد. توجه کنید در این مورد نمیتوان میانه و میانگین را محاسبه نمود چون نام مکانها را نمیتوان به ترتیب عددی قرار داد و آنها را با هم جمع نمود.
وقتی در توزیع فراوانی مقادیر غیر معمولی خیلی بزرگ یا خیلی کوچک داشته باشیم میانه را به کار میبریم زیرا در این موارد میانگین یک نتیجه غیرعادی و تحریف شده برای گرایش به مرکز به ما میدهد.
برای مثال، حداکثر سرعت شش هواپیما به شرح زیر است: 450، 480، 500، 530، 600 و 1100 کیلومتر بر ساعت. ملاحظه میکنید که اغلب آنها سرعتی حدود 500 کیلومتر دارند اما گنجاندن هواپیمای سوپرسونیک با سرعت 1100 کیلومتر باعث میشود که میانگین ما عدد 610 کیلومتر شود. این عدد به عنوان مقدار وسط برای ما مناسب نیست زیرا از حداکثر سرعت 5 هواپیما از 6 هواپیمای ما بیشتر است. اما اگر میانه را که 515 کیلومتر بر ساعت (بین 500 و 530 کیلومتر بر ساعت) برگزینیم. مقدار نمایانگرتری برای نقطه وسط داریم.
با این وجود در اغلب حالات، میانگین معیاری است که برگزیده میشود.
معیارهای پراکنش
تا اینجا دادههایمان را براساس توزیع فراوانی به صورت نمودار رسم کرده و معیار گرایش به مرکز را یافتیم. یک قلم آماری مفید دیگر برای خلاصه کردن دادهها، معیار پراکنش است. به دلایل چندی یافتن پراکنش نمرات مهم است. دو گروه از دانشجویانی که آزمون مشابهی دادهاند میتوانند توزیع فراوانی متفاوتی داشته باشند، درحالیکه میانگین هر دو گروه یکسان باشد. این اختلاف در توزیع را چگونه میتوان بیان کرد؟ تقریباً قطعی است که نمرات یک گروه از دانشجویان پراکندهتر از گروه دیگر است.
پراکندگی کم در نتایج یک تحقیق اغلب به عنوان یک معیار خوب در نظر گرفته میشود زیرا نشان میدهد همه افراد (یا هر چیزی که امتیازها را تولید میکند) مشابه هم رفتار میکنند و در نتیجه مقدار میانگین می تواند بخوبی نمایانگر همه نمرات باشد. پراکندگی زیاد ممکن است یک مشکل باشد زیرا بیانگر آن است که تفاوت زیادی بین نمرههای انفرادی وجود دارد و میانگین نمیتواند بخوبی بیانگر نمرات باشد. بدین دلیل ما نیازمند یک قلم آماری هستیم که وقتی نمرات نزدیک به هم گرد آمدهاند عددی کوچک و وقتی از هم دور هستند عددی بزرگ به ما بدهد (تا به خوبی بیانگر وضعیت نمرات باشد) .
دامنه تغییرات
آسانترین معیار پراکنش دامنه تغییرات است. دامنه تغییرات، اختلاف میان بالاترین و پائینترین نمره است. در مثال ما بالاترین نمره 90 و پائینترین نمره صفر بوده، بنابراین دامنه تغییرات 90 خواهد بود.
این معیار کمی ناپخته است زیرا مرزهای نمرات را مشخص کرده ولی چیزی راجع به پراکنش عمومی آنها نمیگوید. در واقع حتی اگر نمرات به طور یکسان بین صفر تا 90 پخش شده بودند و نه به صورت دسته ای در اطراف نمره 50، دامنه تغییرات بازهم 90 میبود. این قلم آماری تنها اطلاعات دو نقطه را به کار میبرد، در میان این دو نقطه بقیه هر چیزی میتوانند باشند بنابراین اطلاعات محدودی را به ما می دهند.
چارکها
راه دیگر برای نظر به پراکنش، محاسبه چارکهاست. پیش از این دیدیم میانه، دادههای مرتب شده را به دو نیمه تقسیم میکند، خیلی ساده چارکها دادههای مرتب شده را به چهار قسمت تقسیم میکنند. اولین چارک بالاترین نمره ربع اول فهرست ما از پائین به بالاست. و چارک دوم بالاترین نمره ربع دوم بهمان ترتیب است. خیلی طول نخواهد کشید تا دریابیم که چارک دوم وسط فهرست و در نتیجه همان میانه است. چارک سوم هم بالاترین نمره ربع سوم بهمان روش و چارک چهارم بالاترین نمره ربع چهارم یعنی آخرین و بالاترین نمره است.
از فهرست صدتایی مرتب شده نتایج آزمون ما، چارک اول آن، بین نمره نفر 25 و 26 که نمرات آنها 48 و 49 است یعنی 5.48 است. از پیش میدانیم که چارک دوم (بین نمرات نفر 50 و 51) 55 است که در بالا بعنوان میانه بدست آوردیم. چارک سوم بین نمرات نفرات 75 و 76 بوده که عبارتست از 5.59 و البته چارک چهارم 90 بوده که بیشترین نمره است. اگر علامت Q را برای چارکها به کار ببریم خواهیم داشت:
Q1 = 48.5 , Q2 = 55 , Q3 =59.5 , Q4 = 90
یک معیار کمی بهتر برای پراکنش از دامنه تغییرات، دامنه میان چارکی است که به صورت اختلاف بین چارک سوم و اول یعنی Q3-Q1 محاسبه میشود.
در مثال ما این عدد 11 (5.48 – 5.59) است. این دامنه تغییرات نیمی از نمرات است که در وسط توزیع فراوانی واقع شدهاند. علت کاربرد دامنه میان چارکی آن است که این قلم آماری تحت تأثیر یک نمره خاص بالا یا پائین نبوده و میتواند توزیع نمرات را به طرز صحیح تری نشان دهد. (بعضی افراد معیاری مشابه دامنه میان چارکی، را که نصف آن باشد به کار میبرند که در مثال ما 5/5 است).
محاسبه چارکها بسیار سودمند است زیرا چند نکته جالب راجع به توزیع را به ما نشان میدهد. بویژه اینکه آیا توزیع نسبت به میانه متقارن است. Q2-Q1 دامنه تغییرات ربع زیر میانه وQ3-Q2 ، دامنه تغییرات ربع بالای میانه را به ما میگویند. در مثال ما اولی 5.6 و دومی 5.4 است. در ربع بالای میانه نمرات به یکدیگر نزدیکتر از ربع زیر میانه هستند، زیرا عدد 5.4 برای همان تعداد نمره به دست آمده و از 5.6 کوچکتر است.
قابل ذکر است که هر آماره ی جدیدی اطلاعات متفاوتی از داده ها را به ما عرضه می کند. گاهی اوقات ممکن است با نظر به توزیع دادهها چیزی مشخص باشد، اما اغلب آمار با ذکر یک عدد آن را روشنتر و صریحتر میسازد. بهرحال آماره ها به صورت جادویی ظاهر نشده بلکه بوسیله افرادی که به دنبال یافتن راههایی برای بهترین روش توصیف دادهها هستند ایجاد میشوند. وقتی بخواهیم دادههایمان را توصیف کنیم مناسبترین آماره را برای آن برمیگزینیم.
تغییرات
محاسبه چارکها از همه اطلاعات نمرات دادهها استفاده نمیکند و همانطور که در بحث میانه گفتیم با وجود اختلاف نمرات، محدوده میان چارکی میتواند یکسان باشد. سوال اکنون این است که آیا میتوان معیاری برای پراکندگی ابداع کرد که همه نمرات را در نظر بگیرد؟ در پاسخ به این سوال بوده که تعدادی معیار پراکندگی ایجاد شده است.
ویژگی مشترک همگی این معیارها به کار بردن میانگین است (که بار دیگر به اهمیت میانگین دلالت دارد) و منطق آنها به شرح زیر است. اگر میانگین را بعنوان نقطه مرکزی در نظر بگیریم آنگاه میتوان فاصله هر نمره را تا میانگین حساب کرده و دید که چقدر با میانگین اختلاف داشته و از آن انحراف دارد و در آن صورت معیاری از تغییرات کل دادهها داریم. اگر بخواهیم میتوانیم این جمع کلی را بر تعداد نمرات تقسیم کرده تا متوسط انحراف از میانگین را بیابیم.
اگر یک نمره را x در نظر گرفته و میانگین را باµ شان دهیم به سادگی میتوانیم انحراف هر نمره از میانگین را با X − µ محاسبه کنیم. این کار را میتوانیم برای تمامی نمرات انجام دهیم. با این وجود یک مشکل باقیست وقتیکه تغییرات و انحراف نمرات از میانگین را با هم جمع میکنیم.
تغییرات یکدیگر را حذف میکنند. در مثالی که داشتیم انحراف نمره 55 از میانگین برابر 38.2+ = 62.52 – 55 و انحراف نمره 50 از میانگین برابر 62.2- = 62.52 – 50 است. اگر این دو را باهم جمع کنیم خواهیم داشت 38.2 بعلاوه 62.2- که حاصل عدد 24.0- خواهد شد. یعنی بدلیل انجام عملیات منها، جمع دو انحراف از میانگین کمتر از هرکدام از آنها خواهد شد.
ما این را نمیخواهیم. این آماری نیست که بتواند واقعیت را آنگونه که هست نشان دهد. در واقع از آنجائیکه میانگین نقطه تراز همه نمرات است، حاصل افزودن همه انحراف از میانگینها به یکدیگر عدد صفر خواهد بود. چون انحراف از میانگینهای مثبت، دقیقاً انحراف از میانگینهای منفی را حذف میکنند. چون مجموع انحراف نمرات ما هرچه که باشند همیشه برابر صفر خواهد شد، بعنوان یک قلم آماری بیاستفاده است. زیرا قطعاً معیاری از چگونگی پراکندگی نمرات به ما نخواهد داد.
اگر به علامت منفی همه انحراف از میانگینها توجه کنید، متوجه خواهید شد که حاصل همیشه کمتر از میانگین خواهد بود. در واقع ما علاقهای به این نداریم که حاصل بزرگتر یا کوچکتر از میانگین باشد. تنها چیزی که ما میخواهیم آن است که هر نمره چقدر با میانگین فاصله دارد. آنچه اکنون نیازمندیم پیدا کردن راهی است که جمع کردن انحراف از میانگین ها باعث حذف یکدیگر نشود تا حاصل آن تخمینی از تغییرات واقعی نمرات باشد. در این مورد دو راه حل وجود دارد:
انحراف متوسط از میانگین
میتوان مشکل را به این روش حل کرد که علامت منفی را نادیده گرفته و همه انحرافها را بعنوان مثبت در نظر بگیریم. مثلاً اگر یک انحراف از میانگین 62.2- باشد آن را 62.2 حساب میکنیم. با گذاشتن دو خط عمودی در کنار فرمول مشخص میکنیم که قدرمطلق را میخواهیم بنابراین علامتهای منفی را نادیده میگیریم. انحراف مطلق (انحراف متوسط از میانگین) برابر است با |X − µ|. انحراف همه نمرات را با هم جمع زده و برای یافتن انحراف میانگین آنها را بر تعداد نمرات که با N نشان داده می شود،تقسیم می کنیم. ما این را انحراف مطلق میانگین نامیده و به صورت زیر نشان می دهیم:
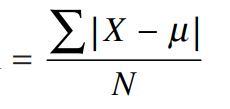
برای مثال نمرات آزمون نتیجه انحراف خواهد شد.
واریانس
یک راه حل دیگر به جای قدرمطلق گرفتن مقادیر، محاسبه مربع یعنی به توان دو رسانیدن انحرافهاست چون مربع اعداد همیشه مثبت است. مربع 16.2- برابر 67.4 است. سپس مربع تمام انحراف از میانگینها را جمع کرده تا مجموع مربعات یعنی به دست آید. آنگاه برای یافتن متوسط مربع انحرافها، رقم بدست آمده را بر تعداد نمرات تقسیم میکنیم. این عدد را واریانس مینامیم.
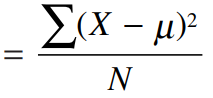
در مثال ما واریانس برابر 52.176 خواهد بود.
واریانس تصویری از تغییرات مقادیر در اطراف میانگین به ما میدهد که به عنوان انحراف مربعات از آن یاد میشود. این مقیاس آنچه را که به دنبال آن بودیم به ما ارائه می دهد، بدین ترتیب که برای نمرات پراکنده عددی بزرگ و برای مقادیر نزدیک به هم میزانی کوچک ارائه می دهد.
جالب آنکه چون واریانس با مربع انحرافها سروکار دارد، وزن بیشتری برای مقادیر بسیار بزرگ قائل میشود. برای نمونه نمرهای که انحراف آن از میانگین 2 باشد با عدد 4 و نمرهای که انحراف آن 4 باشد با 16 در واریانس مشارکت خواهد کرد. بنابراین با وجود آنکه انحراف نمره دوم دو برابر نمره اول است، اما مشارکت آن در واریانس 4 برابر نمره اول خواهد بود.
اگر فقط یک معیار تغییرپذیری نیاز داشتیم واریانس عالی بود اما توجه داشته باشید عددی را که محاسبه کردیم یعنی 66.172 را نمیتوان در توزیع فراوانی به عنوان فاصله از میانگین گذاشت. زیرا واریانس متوسط مربع انحراف از میانگین ها و نه متوسط انحراف از میانگین هاست. برای برگرداندن این قلم آماری به آنچه شروع کرده بودیم باید جذر (ریشه) آن را محاسبه کنیم. (همانطور که قبلاً برای رهایی از علامت منفی انحرافها را به توان 2 رسانیدیم اکنون که منظور ما حاصل شده، لازم است آن را به حالت اول بازگردانیم). این قلم آماری یعنی جذر واریانس را انحراف استاندارد یا انحراف معیار نامیده و آن را با علامت (حرف کوچک یونانی سیگما) نشان میدهیم.
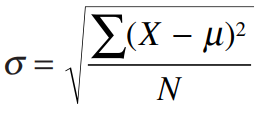
یک مثال ساده نشان میدهد که چگونه انحراف استاندارد یا انحراف معیار را محاسبه میکنیم. فرض کنید که تنها چهار نمره 2و 2 و 3 و 5 در مجموعه دادههایمان داریم. در این صورت میانگین ما 3 خواهد بود.
برای بدست آوردن به شرح زیر عمل میکنیم.
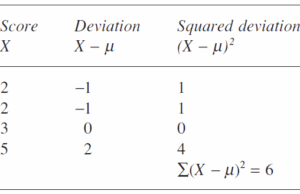
با تقسیم مجموع مربعات
![]()
بر تعداد نمرات (N=4) واریانسی برابر 5.1 به دست میآید. با گرفتن جذر 5.1 انحراف استانداردی* برابر 22.1 = حاصل میشود. در مثال آزمون انحراف استاندارد* یکصد نمره برابر 29.13 است.
انحراف استاندارد* معیاری برای پراکندگی در اطراف میانگین به ما میدهد. در بسیاری از حالات (در حدود دوسوم) اغلب نمرات در طولی باندازه یک انحراف استاندارد کمتر از میانگین تا یک انحراف استاندارد بیشتر از میانگین پراکنده شدهاند یعنی در محدوده تا . در این مجموعه از دادهها، انحراف استاندارد، معیاری از فاصله استاندارد نمرات تا میانگین به ما میدهد.
هشدار: فرمولهای بالا در مورد واریانس و انحراف استاندارد تنها زمانیکه خود دادهها مورد توجه باشند به کار برده میشوند. اما وقتی که دادههای ما زیرمجموعه یا نمونهای از مجموعه دادههای بزرگتری باشد که قصد ارائه آن را داریم فرمولهای کمی متفاوتتری را به کار میبریم. یعنی همان فرمولهای بالا به جز آنکه مجموع مربعها را برخلاف تعداد نمونهها n، بر درجهای از آزادی یعنی df ، تقسیم میکنیم که برابر با df=n-1 تعداد افراد منهای یک است. در مثال ما اگر صد دانشجو کل مجموعه نباشند، بلکه نمونهای از بین هزار دانشجوی شرکت کننده در آزمون بوده که بیرون کشیده شده باشند آنگاه باید این فرمول را به کار ببریم:
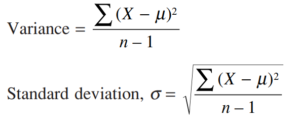
اغلب اوقات ما فرمول را با n-1(درجه آزادی) و نه n (تعداد نمونهها) به کار میبریم زیرا بیشتر اوقات ما علاقه مند به تعمیم نتایج از نمونه به کل جامعه هستیم تا اینکه بخواهیم با کل جامعه سرو کار داشته باشیم.
مقایسه معیارهای پراکندگی
همانند معیارهای گرایش به مرکز، محاسبه معیارهای پراکندگی که بسیار مفید است هم به دلایل چندی بستگی دارد.
محاسبه دامنه و دامنه میان چارکی هر دو آسان بوده و معیاری محدود ولی محتملاً کافی از پراکندگی ارائه میدهند. ضعف آنها این است که همه نمرات را به حساب نیاورده و ممکن است در توانائی نمایش تغییرات نمرات محدودیت داشته باشند. دامنه بویژه، اگر یک مقدار خیلی کوچک یا خیلی بزرگ وجود داشته باشد نمیتواند پراکندگی عمومی نمرات را منعکس کند.
واریانس معیار خوبی برای تغییرات دادههاست زیرا همه نمرات را به کار برده و اگر دادهها در اطراف میانگین مجتمع باشند عددی کوچک و اگر از میانگین دور باشند عددی بزرگ به ما میدهد. این قلم آماری در بعضی از تحلیلهای آماری بینهایت مهم است.
با این وجود وقتیکه یک مجموعه از دادهها را توصیف میکنیم، واریانس ممکن است خصوصا بعنوان توصیف پراکندگی دادهها مفید نباشد، زیرا عددی که تولید میکند از سنخ نمرات نیست بلکه مربع انحراف از میانگین ها را نشان میدهد. در مثال ما واریانس 52.176 بزرگ بنظر میآید. اما این بدلیل آن است که مربع نمرهها را نشان می دهد.
انحراف متوسط از میانگین و انحراف معیار هر دو آمارهای توصیفی خوبی از پراکندگی یک مجموعه از دادهها هستند. هر دوی آنها اطلاعات همه نمرات را به کار برده و عددی تولید میکنند که متوسط انحراف از میانگین را بوجهی که ما میخواهیم (در مثال ما: به صورت نمره) نمایش می دهند. از آنجا که آنها از نوع نمرات می باشند فهمیدن آنها آسان است . اگر مایل باشیم میتوانیم این ارقام را بعنوان فاصله از میانگین در توزیع فراوانی نشان داده تا به خوبی به صورت گرافیکی نمایش داده شوند.
چرا پراکندگی مجموعه دادههای نتیجه گرفته شده، همیشه در گزارشهای تحقیقی به صورت انحراف معیار به نمایش درآمده و به ندرت در شکل انحراف متوسط از میانگین عرضه میشود؟ اگر دادههایی که توصیف میشوند همه آنهایی باشند که موردنظر ما هستند شکایت و چونو چرایی نیست. اما وقتیکه آنها نمونهای از مجموعه وسیعتری (یک جامعه) باشند که مایلیم ارائه شوند امتیاز واضحی برای به کار بردن انحراف معیار وجود دارد.
در مثال ما یکصد دانشجو فقط همان مجموعه مورد نظر ما بودند. اما اگر هزار دانشجو آزمون داده بودند و صد دانشجوی ما نمونه معرف آنها بودند، آنگاه میباید از انحراف استاندارد استفاده شود. دلایل این کار مربوط به نمونه معرف یک جامعه و به کار بردن نمونه آماری برای تخمین مقادیر جامعه است.
توصیف یک مجموعه از دادهها: نتیجهگیری
هنگام توصیف مجموعهای از دادهها، میخواهیم که توزیع فراوانی را با دو معیار خلاصه کنیم، معیار اول مقدار مرکزی که بیانگر متوسط نمرات بوده و معیار دوم چیزی که بیانگر پراکندگی نمرات است. دو قلم آماری بسیار شایع برای این معیارها بدلیل سودمندی آنها، میانگین و انحراف معیار یا انحراف استاندارد میباشند. خلاصه نتایج آزمون را میتوان با این دو قلم آماری “میانگین = 26.52″و “انحراف استاندارد = 29.13″نشان داد.
مقایسه دو مجموعه از دادهها با آماره های توصیفی
آماره های خلاصه به خوبی و اختصار دادهها را توصیف میکند اما در اغلب حالات افراد مایلند اطلاعات را برای ایجاد نکات خاص به کار برند. در مثال ما یک عضو کمیته ممکن است به استانداردهای متحمل رد شدن یا تأثیر یک تغییر در رویه پذیرش دانشجویان توجه کند. آماره های خلاصه میتواند به گرفتن تصمیم در مورد هریک از این سوالات کمک کند.
توجه کنید نکات برجسته شده توسط عضو کمیته، هر دو به مقایسه نتایج سال گذشته با امسال نیازمندند. محاسبات آماری اغلب فراتر از توصیف دادهها رفته و به ما اجازه میدهد برای پاسخ به پرسشهای تحقیق آنهارا به کار بگیریم و این به طور ثابت و تغییرناپذیر مقایسه نتایج دو مجموعه داده را در بر میگیرد.
در مورد مثال ما، نتایج سال گذشته همان آزمون که در آن صد دانشجو شرکت کرده بودند در زیر نشان داده شده است. توجه داشته باشید که به آسانی نمیتوان مشابهتی بین نتایج آزمونهای دوساله با تنها نظر کردن در دو جدول خام دادهها، یافت. هر دو سال مخلوطی از نمره ها را در خود دارند و در حالیکه میتوان بعضی نتایج جالب همچون بیشترین و کمترین نمره هر سال را استخراج کرد، جداول هیچ راه خوبی برای مقایسه بین دو مجموعه ارائه نمیکنند.
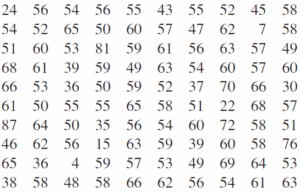
دوباره، اگر دادهها را مرتب کرده و یک توزیع فراوانی درست کنیم ممکن است شروع به دیدن بعضی تفاوتها کنیم. تصویر 2.2 توزیع فراوانی نتایج سال گذشته را نشان میدهد.
حال به صورت چشمی میتوان تصویر2.2 را با تصویر 2.1 مقایسه کرد. توزیع نمرات هر دو سال به نظر شبیه بهم میرسد. این فینفسه ممکن است شاهد مفیدی برای سازگاری کارآیی در هر دو سال باشد. بهرحال، تنها نظر افکندن نمیتواند واقعا به ما بگوید هر دو توزیع فراوانی چقدر مشابه است. زیرا ممکن است تفاوتهای ظریف را از دست بدهیم. این جایی است که آمار به کمک ما میآید.
اگر در ابتدا معیار گرایش به مرکز را ملاحظه کنیم میتوانیم دو سال را مستقیماً مقایسه کنیم.
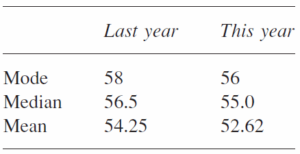
میتوانیم ببینیم که هر سه معیار از سال قبل کمی افت کردهاند. مد به راحتی میتواند تحتتأثیر چند دانشجو تغییر کند و در این حالت قلم آماری خیلی مفیدی نیست. میانه مشخص می کند که نقطه مرکزی سال گذشته کمی بالاتر بوده است. میانگین نسبت به سال گذشته 63.1 نمره افت داشته است. ممکن است این زیاد بنظر نیاید ولی به یاد داشته باشید که میانگین نمره همه دانشجویان را در نظر می گیرد بنابراین به ازای هر دانشجو افتی به اندازه 63.1 داریم.
این مسئله ممکن است به دلایلی باشد که ارزش تحقیق بیشتری را دارد مثل: امسال دانشجویان برجسته کمتری داشتیم یا امتحان امسال مشکلتر از سال گذشته بود. پیش از انجام اینکار میخواهیم یک علت جایگزینی ساده را حذف کنیم. ممکن است سال گذشته تعدادی دانشجوی خوب داشتیم یا امسال تعدادی دانشجوی ضعیف در کلاس بودند.
این مسائل اکنون و دوباره اتفاق میافتد و دلالتی بر آن ندارد که استانداردهای عمومی در حال تغییر است. راهی که میتوانیم از طریق آن به این مسئله نظر کنیم توجه به مسئله پراکندگی است: ممکن است پراکندگی در یکی از این دو سال بیشتر بوده که خود دلالت بر وجود دانشجویان با توانائیهای مختلف در آن سال باشد.
شاخصهای مختلف پراکندگی را میتوان با هم مقایسه کرد.
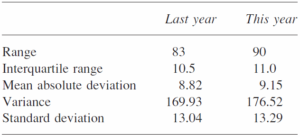
سال گذشته دامنه باریکتری داشتیم چون هیچکس صفر نگرفته بود و بالاترین نمره هم به 90 نمیرسید، اما در دامنه میان چارکی تفاوت چندانی وجود ندارد و خصوصاً و هر دو سال تفاوت چندانی باهم ندارند. ممکن است ارزش داشته باشد که تحقیقات بیشتری در مورد اینکه میانگین نمرات کاهش داشته است، انجام شود. توجه داشته باشید این نتایج به تنهایی نمیتواند علل یک اختلاف را تشخیص دهند، آنها فقط میتوانند ادعا کنند که چیزی اتفاق افتاده است.
دلیلی برای کاهش نسبتا کم در نمرات، خواه پائین بودن قابلیت دانشجویان باشد یا امتحان مشکلتر یا تصحیح سختتر اوراق یا هرچیز دیگر باشد، محقق باید مهارت لازم را داشته باشد تا بتواند آن را بیابد.
همانگونه که از ارقام بالا دیده میشود، میانگین و انحراف استاندارد معمولاً آگاهیدهندهترین آماره ها برای یک توزیع خاص هستند. آنها آماره هایی هستند که بیشتر اوقات انتخاب میشوند اما حالاتی هم ممکن است پیش بیاید که شما فکر کنید آماره هایی دیگر مناسبتر هستند یا چیزی را که میخواهید دقیقتر به شما میگویند.
این مسئله ما را به یک نکته مهم هدایت میکند: آماره ها تا زمانیکه ندانید برای چه آن را انجام میدهید و از آنها میخواهید چه چیزی را به شما نشان دهند، ارزش محاسبه ندارند. ممکن است دادههای خام هرچه را نیاز به دانستن آن دارید به شما بگویند، بنابراین خودتان را با محاسبات آماری اذیت نکنید. بهرحال بیشتر اوقات دیدن ویژگیهای مهم دادهها بدون انجام بعضی از تحلیلها، میسر نمیباشد.
محاسبات آماری مناسب به شما کمک میکند تا تصمیم بگیرید چه پاسخهایی به پرسشهایتان بدهید. مشکل در توصیف و تحلیل دادهها محاسبات آماری نیست (ما برنامههای کامپیوتریی داریم که این کار را انجام میدهند) بلکه در دانستن سوالاتی است که شما میخواهید برای آنها پاسخی بیابید و آماره هایی که به دادن آن پاسخها کمک میکنند.
همچنین، توجه داشته باشید که محاسبات آماری تنها به شما اطلاعات میدهند. این دیگر به شما بستگی دارد که چگونه آنها را تفسیر کرده و به کار ببرید. تفاوت در میانگینها یا، میتواند اطلاعات مفیدی باشد اما این فقط همین است. محاسبات آماری مشابهتها و اختلافات بین توزیع را شرح نمیدهد. آنچه اقلام آماری انجام میدهد تهیه قطعاتی از اطلاعات است که میتوانیم با آنها کار کنیم: آنها ابزاری هستند که برای مقصود خود به کار میبریم. بعد از آن باید خودمان قضاوت کنیم.
جزئیات تولید اقلام آماری برای توصیف یک مجموعه از داده ها با استفاده از بسته نرم افزاری SPSS در فصل 3 کتاب Hinton.et al (2004) آمده است.
اطلاعات مهمی درباره اعداد
تاکنون محاسبات آماری را با استفاده از مجموعه ای از نمرات آزمون انجام دادیم. این خوب است زیرا نتایج آزمون نوعی از اعداد هستند که محاسبه میانگین و دیگر اقلام آماری آنها معقول است. اما همه اعداد به این شکل نیستند. پیش از آنکه بدانیم قادر به محاسبه کدامین اقلام آماری هستیم نیازمندیم تا بدانیم چه نوع دادههایی داریم.
دادههای اسمی
گاهی اوقات اعداد مثل اسامی هستند. برای نمونه در یک بازی که 22 بازیکن دارد عدد 15 روی پشت یک بازیکن تنها امکان شناسایی او را در حین بازی میدهد. این بدان معنا نیست که بازیکن شماره 15 بهتر از بازیکنان شماره 1 تا 14 بوده و یا بدتر از بازیکنان شماره 16 تا 22 است. محاسبات آماری روی این اعداد بیارزش و بیمعناست زیرا آنها اعداد اسمی هستند که به عنوان نام به کار برده میشوند.
وقتیکه چیزی یا کسی را دستهبندی میکنیم میتوانیم برای عنوان هر دسته از عدد استفاده کنیم. برای مثال، اگر افراد را براساس رنگ چشم دستهبندی کنیم ممکن است به قهوهای شماره 1، آبی شماره 2، سبز شماره 3 و بهمین ترتیب آنها را عنوانگذاری کنیم. توجه کنید در اینجا اعداد بصورت قراردادی به رنگها اختصاص داده شدهاند.
میتوانیم اعداد دیگری را برگزینیم یا همان اعداد را به روش دیگری اختصاص دهیم. استفاده از این اعداد به صورت اسمی است و از آنها نمیتوان برای محاسبات آماری استفاده کرد و چهار عمل اصلی را نمی توان روی آنها انجام داد. بیمعنی است که بگوئیم میانگین افراد چشمقهوهای یک و چشم سبزها 3 و چشم آبیها 2 است.
دادههای ترتیبی
میتوان اعداد را برای مشخص شدن ترتیب کارآیی به کاربرد برای نمونه سوزان بهترین شطرنجباز کلاس و بعد از او به ترتیب روبرت، ماری و پیترهستند. میتوانیم به سوزان رتبه یک، روبرت 2، ماری 3 و پیتر 4 را بدهیم. این اعداد تنها رتبه افراد را نشان میدهند. آنها به ما نمیگویند که تفاوت بین رتبه 1 و 2 (سوزان و رابرت) مثل تفاوت بین رتبه 3 و 4 (ماری و پیتر) است.
علیرغم آنکه در رتبهبندی بین آنها تنها یکی فاصله است. سوزان ممکن است در سن خودش بهترین بازیکن کشور باشد. در حالیکه سه نفر دیگر ممکن است به خوبی نفرات مدارس نزدیکشان هم نباشند. بدین دلیل نمیتوانیم میانگین و انحراف استاندارد را در مورد اعداد ترتیبی به کار ببریم.
دادههای نسبتی و فاصله ای
زمان، سرعت، مسافت و درجه حرارت همه را میتوان با مقیاسهای فاصله ای اندازه گرفت. همه ما برای این کارها ساعت، سرعت سنج، متر و دماسنج داریم. ما آنها را مقیاسهای بازهای یا فاصله ای می نامیم زیرا تفاوت میان اعداد متوالی، فواصل و بازههای متساویست. تفاوت بین 1 و 2 همان فاصله بین 3 و 4 یا 10 و 11 است. برخلاف مقیاسهای ترتیبی که میتوانند متفاوت باشند در دادههای بازهای فواصل یکسانند. برای مثال فاصله بین 6 و 7 دقیقه همان فاصله بین 20 و 21 دقیقه، یعنی در هر حالت یک دقیقه است. وقتی اعداد ما از مقیاسی نشأت گرفتهاند که فواصل مساوی دارد میتوانیم میانگین و انحراف استاندارد را محاسبه کنیم.
دادههای نسبتی نوع خاصی از دادههای بازهای هستند با دادههای فاصله ای مقدار صفر میتواند قراردادی باشد. مثل نقطه صفر در مقیاسهای درجه حرارت: صفر فارنهایت با صفر سلسیوس در موقعیتهای متفاوتی هستند. در حالیکه در دادههای نسبی صفر نمایانگر نقطه ای در مقیاس است که واقعا چیزی وجود ندارد مثل صفر در سرعتسنج که نشانه عدم حرکت است بنابراین صفر صرفنظر از اینکه با مایل در ساعت یا کیلومتر در ساعت اندازهگیری کنیم یک معنا دارد.
با مثال زیر این تفاوت را تشریح میکنیم. در مثال آزمون، ما 100 سوال با سختی یکسانی داشتیم و دانشجویان برای گرفتن نمره قبولی نیاز به حداقل 50 پاسخ صحیح داشتند. امتحان گیرنده میتواند نمره قبولی بگذارد یعنی نمره صفر نمایانگر 50 پاسخ صحیح باشد، 1 نمایانگر 51 پاسخ و 1- نمایانگر 49 پاسخ صحیح و به همین ترتیب این یک مقیاس بازهای با صفر قراردادی است.
آزمون گیرنده تصمیم میگیرد که صفر را کجا بگذارد. حالا بیائید همان امتحان را به شکلی در نظر بگیریم که نمره صفر نمایانگر عدم وجود پاسخ صحیح بوده و نمره قبولی 50 باشد. در این حالت صفر دیگر قراردادی نیست چون نمایانگر هیچ پاسخ صحیح در آزمون است. در اینجا مقیاس فاصله ای تبدیل به مقیاس نسبتی میشود.
تنها در مقیاسهای نسبتی با صفر واقعی، میتوانیم ادعاها را با نسبت نشان دهیم مثل آنکه: نمره سوزان دوبرابر بهتر از نمره جان و نمره روبین یک سوم نمره پیتر است. اگر نمره سوزان 80 و جان نمره 40در آزمونی با مقیاس نسبتی گرفته باشند. آنگاه نمره او واقعاً دو برابر نمره جان است.
در مقیاس بازهای با صفری که به صورت قراردادی روی نمره 50 قرار داده شده باشد نمره آنها 30 و 10- خواهد بود. در مقیاسهای فاصله ای ما قادر به قضاوتهای نسبی درستی نیستیم. بسیاری از آماره ها نیازمند دادههای نسبتی یا فاصله ای هستند. دادههایی را مورد ملاحظه قرار میدهیم که دادههای نسبتی یا فاصله ای باشند زیرا این نوع دادهها به ما امکان انجام گستردهترین آزمایشهای آماری را میدهند.
بهمین دلیل محققین اغلب جمعآوری دادههای نسبتی یا فاصله ای را برای تحلیل انتخاب میکنند. در تحقیقات انسانی، تحقیق اغلب بر روی اینکه یک کار چقدر سریع و چقدر دقیق میتواند انجام گیرد است زیرا هم سرعت و هم دقت را میتوان با مقیاس نسبتی اندازه گرفت.
مترجمین: دکتر هدی کامرانی فر – حسن اسکندری نیا




