رگرسيون و همبستگی خطی – بخش 2
20 دی 1400
دقیقه
در مقاله قبلی به بخش اول رگرسيون و همبستگی خطی پرداختیم. در این فصل به آموزش ادامه آن، در ادامه سری مقالات آموزشی آمار به زبان ساده می پردازیم.

آخرین بهروزرسانی: 24 دی 1401
در مقاله قبلی به بخش اول رگرسیون و همبستگی خطی پرداختیم. در این فصل به آموزش ادامه آن، در ادامه سری مقالات آموزشی آمار به زبان ساده می پردازیم.
رگرسیون خطی
در بعضی از کتابها همبستگی خطی از رگرسیون خطی با قرار دادن آنها در فصلهایی جداگانه تفکیک می شوند. این کار شاید باعث مرتب تر شدن نوع بیان شود اما نباید مانع این حقیقت شود که همبستگی و رگرسیون مانند دو طرف یک سکه هستند. رگرسیون خطی بیان کننده ی چگونگی بیان رابطه ی نزدیک دو متغیر تحت یک خط مستقیم صحبت می کند.
زمانی که همبستگی بالایی برقرار باشد (بیشتر یا کمتر) با رسم نمودار پراکنش می توان از چگونگی ایجاد رگرسیون خطی آگاهی یافت. اما زمانیکه میزان همبستگی ضعیف تر باشد نقاط بیشتر پراکنده هستند تا اینکه متمرکز روی یک خط باریک باشند. حال این سؤال مطرح است در صورتیکه همبستگی کمی برقرار باشد باز هم می توان گفت که رگرسیون خطی بین متغیرها برقرار است و خط به چه صورت است؟
همبستگی خطی اطلاعاتی از چگونگی نزدیک بودن رابطه ی دو متغیر به یک خط مستقیم را می دهد. رگرسیون خطی، خطی مستقیم است که به بهترین وجه رابطه ی خطی میان دو متغیر را شرح می دهد. زمانی که همبستگی با میزان بالایی برقرار باشد با رسم نمودار پراکنش قادر خواهیم بود (به صورت بیشتر و یا کمتر) ببینیم خط رگرسیونی کجا قرار خواهد گرفت.
اما زمانی که همبستگی ضعیف باشد نقاط به صورت پراکنده گسترده می شوند به گونه ای که روی یک نوار باریک قرار نگرفته و تشخیص خط رگرسیونی به واضحی حالت قبل نخواهد بود. در چنین حالتی میزان همبستگی پایین بوده و سوالی که مطرح است این است که آیا رابطه ی خطی میان متغیرها به اندازه ی یک خط وجود دارد؟
با استفاده از خط رگرسیونی می توان نمرات یک متغیر را با استفاده از دیگر متغیر پیش بینی کرد. در بخش قبل مشاهده کردیم که r در واقع شیب خط رگرسیونی در ارتباط با نمرات استاندارد z است اما این آنچه که دنبالش هستیم نمی باشد. ما علاقه مند به یافتن خطی هستیم که به بهترین نحو به نمرات واقعی برازش داده شود و بتوان به صورت مستقیم و بدون اینکه بخواهیم به نمرات استاندارد z تبدیل کنیم به پیش بینی نمرات بپردازیم.
در این حال اگر چه تا حدودی مشکل است اما نیاز به اندکی محاسبات ریاضی می باشد. فرمول خط رگرسیونی مستقیم میان دو متغیر X و Y به صورت Y=a+bX است که a و b مقادیری ثابت هستند (اگرچه X و Y متغیرند ولی آنها همیشه ثابت هستند) و X و Y هم دو متغیر مورد نظر می باشند. برای a و b هر مقدار عددی ای می توان در نظر گرفت و پس از آن با قرار دادن این مقادیر و همچنین، مقدار X انتخابی در معادله مقدار Y محاسبه می شود؛ و هر بار با رسم کردن X و Y در یک نمودار نقاط در امتداد یک خط مستقیم قرار خواهند گرفت.
به عنوان نمونه در صورتیکه a=2 و b=3 انتخاب شوند خطی مستقیم به صورت Y = 2 + 3X بدست می آید. برای X هر مقداری مثلا 4 را انتخاب کرده و در نهایت خواهیم داشت Y = 2 + (3 * 4) = 14.
این کار را برای هر X ی می توان انجام داد و پس از آن اگر X ها و Y ها در نموداری رسم شوند مشاهده خواهیم کرد که در امتداد خطی مستقیم قرار خواهند گرفت. زمانی که X = 0 در آن صورت Y = a (در مورد مثال ذکر شده زمانی که X = 0, Y = 2)، بنابراین a نقطه ای است که خط مستقیم برازش شده محور Y را قطع می کند. شیب خط برابر با مقدار ثابت b بوده که بیان کننده ی چگونگی صعود و یا نزول شیب خط است و دقیقاً مشابه با قدم زدن در یک جاده مستقیم است که گاهی اوقات جاده به سمت بالا رفته و در برخی نقاط دیگر باید از تپه ای پایین رفت.
چنانچه مقدار شیب بیش از 1 بدست آید گفته می شود خط شیب دار است و چنانچه محور X را در نظر بگیریم بدین معنی است که در امتداد محور Y در حال بالا رفتن از تپه ای هستیم. با وجود کمترین مقدار برای شیب خط به طور نسبی نزدیک محور X خواهد بود.
شیب کمتر از یک بسیار سطحی بوده و هر چقدر در راستای محور X جلو رویم به ازای هر واحد X مقدار کمی به Y اضافه شده و خط بیشتر نزدیک محور X است تا محور Y . اکنون تلاش کنید با داشتن محور افقی X و محور عمودی Y معادلات تعدادی از خطوط مستقیم را با استفاده از چندین نقطه برای هر خط بسازید.
جهت بدست آوردن خط رگرسیونی دو متغیر تحت مطالعه می بایست از معادلات خط مستقیم استفاده شود. در صورتیکه همبستگی کاملی (r=+1 or -1) میان متغیرها برقرار باشد کلیه نقاط در نمودار پراکنش در امتداد خط مستقیمی که در واقع همان خط رگرسیونی است قرار می گیرند. اما در بسیاری موارد همبستگی به طور کامل برقرار نبوده و خط رگرسیونی وضوح کمتری دارد.
در مدل خطی فرض می شود که با داشتن تغییرات تصادفی نقاط در امتداد یک خط مستقیم قرار می گیرند؛ بنابراین نیاز است با توجه به مجموعه ی داده ها ی موجود خط مستقیمی را که بیشترین نزدیکی به داده ها را دارد بدست آوریم. قابل ذکر است که همبستگی معنی دار اطمینانی از وجود یک رابطه ی خطی حقیقی میان دو متغیر را می دهد. اما زمانی که همبستگی ضعیفی برقرار باشد باز هم می توان خط رگرسیونی را بدست آورد ولی با این تفاوت که دیگر رابطه ی خطی به طور قطع یقین برقرار نیست.
در ابتدا باید متغیری را که می خواهیم در مورد آن پیش بینی انجام دهیم (در مورد مثال ذکر شده عملکرد آزمون، متغیر Y) و متغیری که برای پیش بینی از آن استفاده می شود (زمان مطالعه، متغیر X) مشخص کنیم. اولین مرحله در منطق تجزیه و تحلیل رگرسیون، فرض صحیح بودن متغیر X است و در واقع عدم قرار گرفتن مقادیر Y در امتداد خط مستقیم به علت خطای تصادفی است. تجزیه و تحلیل ها در ابتدا روی مقادیر X صورت گرفته و به صورت فرمول هایی که در ادامه می آیند بیان می شوند:
Y=(X روی) رگرسیون + خطا
Y=Y’+E
فرض می شود که مقادیر واقعی Y ترکیبی از مقادیری که در امتداد خط مستقیم قرار می گیرند(Y’) بعلاوه انحراف ایجاد شده از خط توسط خطای تصادفی است (E). آنچه اكنون مورد نظر است این است كه كدام یك از مقادیر Y كاملاً روی خط مستقیم قرار گرفته و در نتیجه ی آن خطای تصادفی حذف بشود. مقادیر Y’ به صورت Y′ = Y − E كدام ها هستند؟ بنابراین خط مستقیمی كه به دنبال آن هستیم به صورت زیر معرفی می شود:
Y′ = a + bX
كه خط رگرسیونی Y روی X بدون وجود خطا (E) است. اكنون می بایست به دنبال مقادیر مناسب a و b بود.
در مرحله ی بعد تحلیل از خواص “بهترین خط برازش شده” با كمترین مقادیرخطا استفاده می شود؛ و ما به دنبال خطی نیستیم كه از همه ی نقاط نمودار پراكنش فاصله داشته باشد بلكه خط رگرسیونی می بایست نزدیك ترین خط مستقیم به مجموعه ی نقاط داده ها باشد.
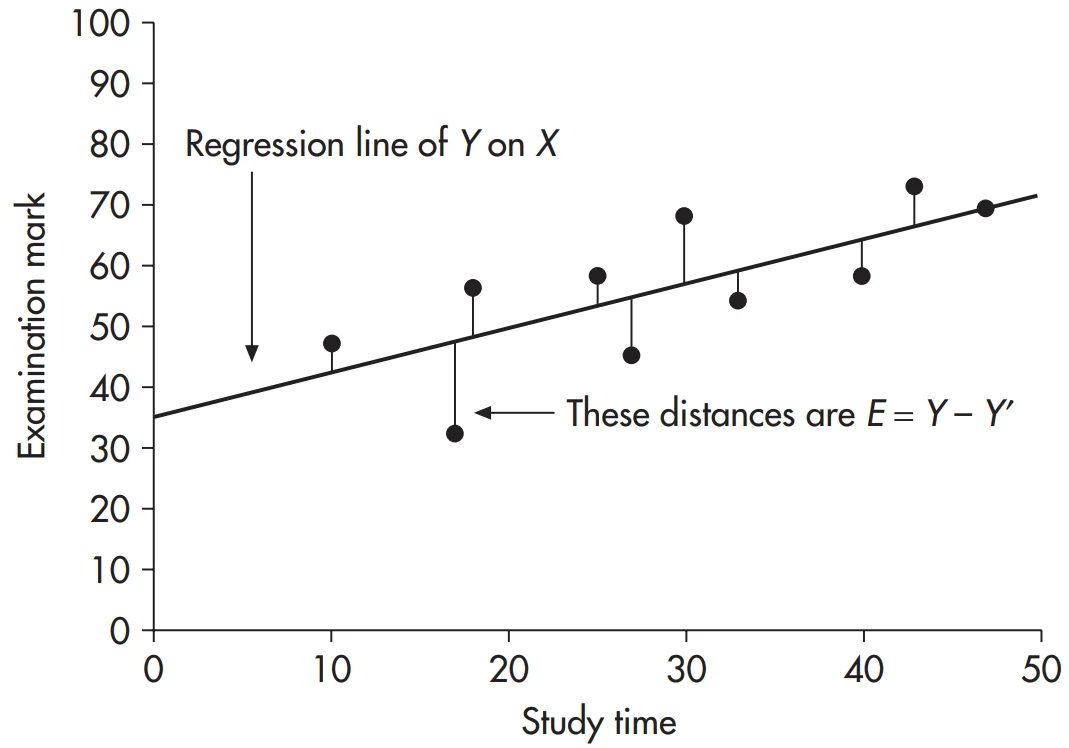
در واقع خطی باید یافته شود كه كوچكترین مقادیر E یعنی E = Y – Y’ را تولید كند. روش محاسباتی و ریاضی انجام این كار حداقل كردن E است كه E همان فاصله ی داده های واقعی از خط رگرسیونی می باشد. نمودار 20.3 نمود این امر در مورد مثال ذكر شده است.
بنابراین مقادیر حداقل E تحت روشی با عنوان روش حداقل مربعات رگرسیون خطی بدست می آیند. جهت بدست آوردن ∑ E = ∑(Y – Y′) باید برای تمامی آزمودنی ها مقادیر خطا (Y-Y’) را با هم جمع كرد اما مشكلی كه وجود دارد این است كه برخی از این مقادیر مثبت و تعدادی دیگر منفی بوده و یكدیگر را خنثی می كنند (همچنانكه از نمودار 20.3 دریافت می شود)، و مقدار خطا از بین می رود. جهت اجتناب از این

سرانجام با جایگزین كردن a و b توسط مقادیر واقعی آنها در فرمول، خط رگرسیونی به صورت زیر فرمول زیر بیان می شود: Y’=34.41 + 0.74X كه اعداد آن تا دو رقم اعشار گرد شده اند.
اكنون از این فرمول با استفاده از مقادیر X (زمان مطالعه) جهت پیش بینی كردن مقادیر Y (عملكرد آزمون) استفاده می شود. در بخش بعد جدولی ارائه شده كه در آن به پیش بینی مقادیر Y با استفاده از رگرسیون روی X پرداخته شده است.
از خط رگرسیونی برای پیش بینی مقادیری دیگر نیز می توان استفاده كرد. به عنوان مثال هیچ كدام از دانشجویان 5 ساعت در هفته مطالعه نمی كنند. حال سؤال این است با این زمان مطالعه دریافت چه نمره E پیش بینی می شود؟ با استفاده از فرمول خواهیم داشت: Y’=34.41 + (0.74 X 35)=60.31 . بنابراین انتظار می رود با زمان مطالعه ی 35 ساعت در هفته نمره ای برابر با 60.31 در آزمون دریافت شود.
ارتباط r و شیب خط رگرسیونی
تاكنون b، یعنی شیب خط رگرسیونی و r، ضریب همبستگی و در واقع شیب خط رگرسیونی نمرات z را یافتیم. رابطه ای ساده میان این دو شاخص برقرار است:

پیش بینی X با استفاده از Y
در تحلیل رگرسیونی هیچگونه راه منطقی دیگری وجود ندارد كه منجر به نتیجه ای متفاوت شود، جز اینكه فرض كنیم مقادیر Y داده شده هستند و این مقادیر X هستند كه به واسطه ی خطا از خط رگرسیونی انحراف پیدا می كنند. به طریقی مشابه از همین راه منطقی جهت پیش بینی X با استفاده از

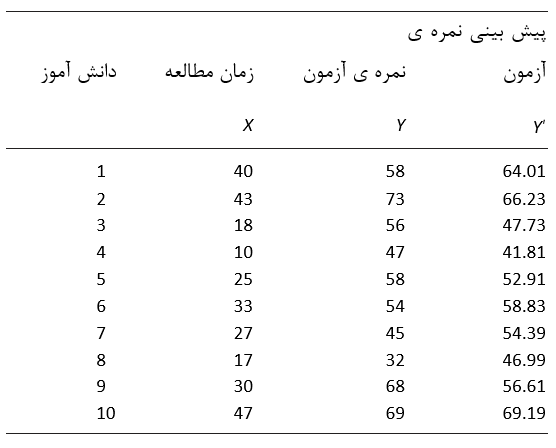
رگرسیونی (Y روی X، و X روی Y) را رسم كنیم مشاهده خواهیم كرد كه بسیار به هم نزدیك خواهند بود. (در مورد مثال ذكر شده شكل 20.4 را ببینید). زیرا هرچه همبستگی قوی تر باشد باعث می شود كه خطوط رگرسیونی بیشتر به هم نزدیك شوند. با وجود همبستگی كامل خطوط دقیقا مشابه یكدیگر می شوند.
هرچه همبستگی ضعیف تر شود خطوط بیشتر از هم فاصل گرفته تا نهایت اینكه r=0 و خطوط متعامد هستند، بدین معنی كه در نهایت زاویه به یكدیگر بوده و هیچگونه ارزش پیشگویی نداشته زیرا همبستگی خطی میان دو متغیر وجود ندارد.
تعبیر همبستگی و رگرسیون
زمانی كه ضریب همبستگی معنی دار می شود می بایست در تعبیر آن بسیار دقت نمود. اولین نکته قابل توجه این است که همچنانكه N افزایش می یابد جهت معنی داری r، مقداری کوچک برای r مورد نیاز است. در آزمونی یك دنباله ای با درجه ی آزادی 70 و یا در آزمون دو دنباله ای با درجه آزادی 100 (در p= 0.05) زمانی كه r مقداری به كوچكی 0.2 باشد باز هم معنی دار است.
در مورد ضرایب همبستگی همین که این مقدار بزرگ بدست آید جهت معنی داری کفایت می کند و یا اینکه باید معنی داری آن دقیقاً مورد برسی قرار گیرد؟ یكی از روشهای تصمیم گیری در مورد اهمیت همبستگی توجه به این مسئله است كه تغییرات نمرات یك متغیر تا چه میزان می تواند توسط تغییرات نمرات سایر متغیرها توضیح داده شود (پیش بینی شود). در صورتیكه ضریب همبستگی معنی دار باشد ولی تنها بتواند تغییرات بسیار جزئی را توضیح دهد ازرش چندانی در پیش بینی ندارد.


می گوید كمتر از نیمی از تغییرات Y توسط تغییرات در X توضیح داده می شود (و بالعكس). همچنین در همبستگی برابر با 0.2 تنها 0.04 از تغییرات Y به وسیله ی رگرسیون روی X تبیین می شود؛ از طرفی با وجود اهمیت آماری این مسئله ناچار به پذیرفتین X به عنوان نوعی پیش بینی كننده ی Y هستیم.
مسائلی در ارتباط با همبستگی و رگرسیون
زمانی كه همبستگی بررسی می شود باید از هم واریانس بودن داده ها اطمینان حاصل كرد. هم واریانسی اساسا بدان معنی است که رابطه بین دو متغیر در تمام نقاط یكسان باقی مانده و مقادیر به طور یكنواخت اطراف خط رگرسیونی پراكنده می شوند. نقاط منفرد و خوشه ها هر دو تأثیری قابل توجه روی ضریب همبستگی دارند و خصوصاَ رمانی مقادیر متغیرها در دامنه ی محدودی به كار روند، باعث پنهان شدن روابط متغیرهای تحت بررسی می شوند.
نكات ذكر شده را با ارائه یك مثال روشن می نماییم. محققی پیش بینی می نماید كه لبخند به روی لب داشتن دستیاران فروش به مشتریها در تعداد كالاهای به فروش رسیده تأثیری بسزا دارد. جهت بررسی این امر تعداد لبخندهای هر كدام از دستیاران فروش از زمان خوش آمد گویی به آنها تا زمانی كه مشتری تصمیم به خرید كالا و یا عدم آن می كند توسط دوربین هایی در طول یك روز مشخص ضبط می شوند.
محقق می خواهد همبستگی میان میانگین زمان لبخند به مشتری (به دقیقه) را برای هر كدام از دستیاران فروش و تعداد كل كالاهای به فروش رسیده هر كدام از دستیاران فروش در طول روز را محاسبه كند. نتایج 9 فروشنده در جدول زیر به نمایش درآمده است.
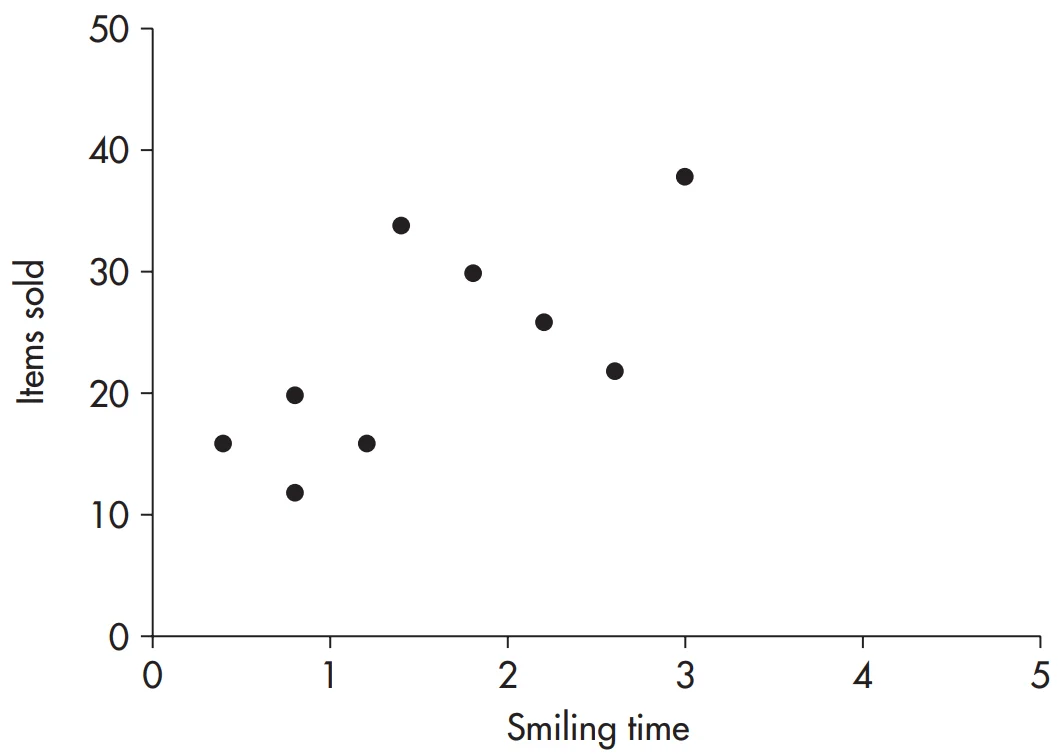
با محاسبه ی ضریب همبستگی با در نظر گرفتن 9 فروشنده خواهیم داشت r = 0.69 SP=43.65 , SSx=6.28 , SSy=627.56 , df=7
كه در سطح معنی داری p<0.05 معنی دار است (با توجه به جدول A.9 ضمیمه ملاحظه می كنیم كه در آزمون یك دنباله ای df=7, p=0.05,r=0.5822). با توجه به نمودار پراكنش شكل 20.6 مشاهده می كنیم كه شركت كننده ی 9 جدای از سایرین است. بدون در نظر گرفتن این فرد خواهیم داشت
SP=20.80 , SSx=4.00 , SSy=400.00 ,df=6 ,r=0.52
كه دیگر معنی دار نمی شود (زیرا در آزمون یك دنباله ای r=0.6215,p=0.05,df=6). در نتیجه اثر وجود شركت كننده ی 9 باعث به اشتباه معنی دار شدن همبستگی می شود، در نتیجه علیرغم معنی دار شدن آماری آن در عمل قابل استفاده نیست. این مسئله نشاندهنده ی اثر قوی “مشاهده ی پرت” بر همبستگی است.


مثال کاربردی
از دو معلم درخواست شد تا هر دو نفر در مورد متغیر “چگونگی خوب انجام دادن امور تحصیلی در دانشگاه” در فاصله 0 تا 20 بر حسب بعید تا احتمال زیاد به شش نوجوان امتیازی بدهند. نتایج در جدول زیر نشان داده شده اند. آیا همبستگی مثبتی میان رتبه دادن معلمان وجود دارد؟
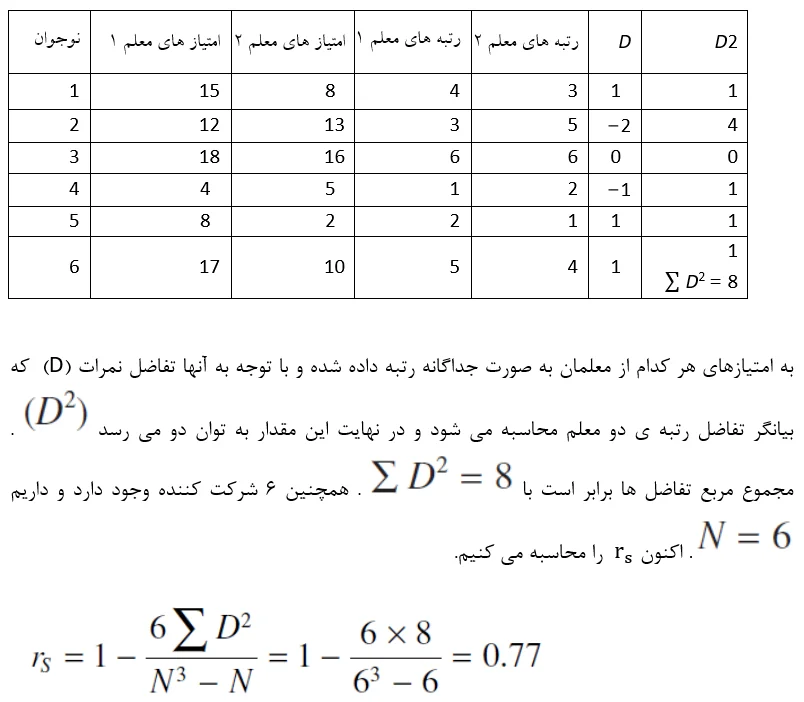
از آنجاییکه پیش بینی در مورد همبستگی مثبت است با آزمونی یک دنباله ای مواجه هستیم. با توجه به جدول A.10 ضمیمه در مورد آزمون یک دنباله ای خواهیم داشت، rS = 0.829, p = 0.05, N = 6. مقدار محاسبه شده بیشتر از مقدار جدول نیست و نتیجه می گیریم که همبستگی معنی داری میان رتبه ها وجود ندارد. (باید توجه داشت که با وجود تعداد کم آزمودنی ها، جهت معنی داری ضریب همبستگی نیاز به یک مقداری که از نظر عددی بالا باشد است.)
جهت بررسی جزئیات بیشتر در مورد چگونگی محاسبه ی همبستگی خطی و رگرسیون خطی با استفاده از پکیج آماری SPSS به فصل 15 کتاب Hinton et al. (2004) مراجعه شود.
مترجمین: دکتر هدی کامرانی فر – حسن اسکندری نیا




