كامپيوتر و تحليل های پيچيده – بخش 2
11 بهمن 1400
دقیقه
تحلیل عاملی روشی است که رابطه ی میان نمرات بدست آمده از اقلام مختلف را آزمون کرده و از همبستگی میان آنها برای تعیین قوی بودن نسبی جهت اثبات وجود عواملی در تحقیق استفاده می کند. این روش به گونه ای نیست که علاقه مند باشیم به صورت دستی با آن کار کنیم. در گذشته تحلیل عاملی تنها توسط آماردانها انجام می شد به گونه ای که جهت تعیین عوامل مجموعه ای از داده ها ساعت های زیادی صرف انجام محاسبات می شد.

آخرین بهروزرسانی: 24 دی 1401
در مقاله قبلی به بررسی بخش اول كامپيوتر و تحليل های پيچيده پرداختیم. در این فصل به آموزش ادامه آن، در ادامه سری مقالات آموزشی آمار به زبان ساده می پردازیم.
تحليل عاملی
در مثال ذکر شده در بخش قبل مشاهده کردیم که مقدار پایایی اقلام پرسشنامه مذکور مقداری بالا و قابل قبول (آلفا=0.83) بدست آمد، بنابراین می توان به همان صورتی که هست از آن استفاده کرد. در صورتیکه پرسشنامه پایایی کمی داشته باشد بیانگر این است که نمرات بدست آمده به ازای اقلام مختلف به گونه ای سازگار تغییر نمی کنند و دلیل این امر ممکن است سؤالهای متفاوتی باشد که به گونه ای نامناسب برای عوامل تحت بررسی در نظر گرفته شده اند. به عنوان مثال جهت انجام آزمونی شناختی از گروهی از کودکان در چهار زمینه ی حساب، هندسه، استدلال کلامی و قوه ادارک داستان آزمونی به عمل آمده است. در حین انجام این آزمون ممکن است دریابیم همبستگی بالایی میان نمرات بدست آمده از حساب و هندسه و همچنین همبستگی بالایی نیز میان استدلال کلامی و قوه ادارک داستان وجود دارد، در حالیکه همبستگی میان نمرات حساب و استدلال کلامی، حساب و قوه ادارک داستان، هندسه و استدلال کلامی، هندسه و قوه ادراک داستان پایین است. بنابراین می توان گفت نمرات حساب و هندسه به یکدیگر وابسته هستند و همچنین نوعی همبستگی میان نمرات استدلال کلامی و قوه ادارک داستان وجود دارد و این امر (احتمالاً) نشاندهنده ی وجود دو عامل در تحقیق بوده که می توان آنها را تحت عناوین “توانایی ریاضی” و “توانایی زبانی” نام نهاد.
تحلیل عاملی روشی است که رابطه ی میان نمرات بدست آمده از اقلام مختلف را آزمون کرده و از همبستگی میان آنها برای تعیین قوی بودن نسبی جهت اثبات وجود عواملی در تحقیق استفاده می کند. این روش به گونه ای نیست که علاقه مند باشیم به صورت دستی با آن کار کنیم. در گذشته تحلیل عاملی تنها توسط آماردانها انجام می شد به گونه ای که جهت تعیین عوامل مجموعه ای از داده ها ساعت های زیادی صرف انجام محاسبات می شد.
تحلیل عاملی روشی برای تلخیص داده ها است که در آن قادریم بررسی کنیم آیا عواملی که بتوانند تغییرات متغیرهای تحت مطالعه را توضیح دهند وجود دارند یا خیر؛ و البته توانایی توضیح دادن تغییرات مجموعه ی داده ها توسط تعدادی از عوامل که تعداد آنها کمتر از تعداد متغیرهای تحت مطالعه است، روشی سودمند محسوب می شود. این کار به دو روش قابل انجام است: اکتشافی (جهت شناسایی عوامل) یا تأییدی (جهت تأیید عوامل پیشنهاد شده). در این مثال تحلیل عاملی اکتشافی را مورد بررسی قرار خواهیم داد.
اولین نکته در بررسی تحلیل عاملی بررسی مناسبت داده ها جهت انجام این روش است. همچنین جهت حصول اطمینان از اینکه همبستگی ها نماینده مناسبی از مقادیر مشابه در جمعیت باشند، می بایست نمونه به اندازه کافی بزرگ انتخاب شود. برخی قوانین پیشنهادی وجود دارند که لزوم اهمیت بزرگ بودن مجموعه ی داده ها را نشان می دهند: به طور کلی می بایست حداقل 200 داده وجود داشته باشد به گونه ای که به ازای هر کدام از اقلام حداقل 10 داده و همچنین تعداد آزمودنی های باید حداقل پنج برابر اقلام باشند. به وضوح مشاهده می شود که تعداد داده ها در مورد مثال ذکر شده جهت استخراج معیارهای یاد شده کافی نیست، منتها صرفاً جهت نمایش دادن چگونگی انجام کار مثال را ادامه خواهیم داد.
معمولاً قبل از انجام تحلیل عاملی دو آزمون سودمند انجام می شوند. آزمون KMO (Kaiser–Meyer–Olkin)، کفایت داده های نمونه گیری شده را بررسی می کند و نوعی اندازه گیری واریانس درون داده هاست و مقیاسی برای بررسی توانایی عاملی بودن ارائه می دهد. دامنه ی آماره ی KMO بین 0 تا 1 است. در مورد مثال بررسی شده این آماره برابر با 0.655 است. هر مقداری بزرگتر از 0.6 برای انجام تحلیل عاملی قابل پذیرش است و مقادیری کمتر از آن بدین معنی است که تحلیل عاملی توانایی به پوشش تغییرات داده ها را نداشته و لذا انجام آن ارزشی ندارد.
آزمون دوم، آزمون کرویت بارتلت است که در آن ماتریس همبستگی مورد بررسی قرار داده می شود (بخش قبل را مشاهده کنید). در صورتیکه هیچگونه همبستگی میان متغیرها وجود نداشته باشد، به غیر از مقادیر قطر اصلی که 1 هستند، سایر مقادیر صفر خواهند بود و به آن ماتریس همانی گفته می شود.

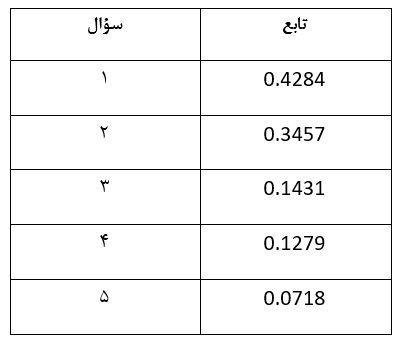
اکنون با توجه به آزمونهای انجام شده در بخش قبل اطمینان داریم که تحلیل عناصر اصلی جهت یافتن عوامل موجود قابل انجام است. جهت انجام، داده های کلیه اقلام استاندار با میانگین 0 و انحراف معیار 1 شده اند. بنابراین واریانس هر کدام از اقلام یا متغیرها 1 خواهد شد و با وجود 5 متغیر، واریانس کلی که تبیین می شود برابر با 5 خواهد بود. پس از آن عوامل شناسایی می شوند. هر کدام از عوامل مقدار ویژه ای دارد که بر حسب واریانسی از کل داده ها که توسط آن عامل توضیح داده می شود، وزنی به خود اختصاص می دهد. این مقادیر در جدول زیر نمایش داده شده اند.
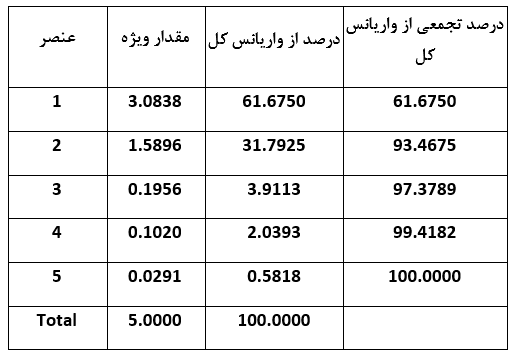
با توجه به جدول مشاهده می شود که 5 عنصر یا عامل شناسایی شده اند. بر حسب قاعده کلی تنها عوامل با مقدار ویژه بیش از 1 توانایی شناسایی به عنوان عاملی که قابلیت توضیح دادن بخش قابل توجهی از واریانس را داراست، به عنوان یک قلم جداگانه می باشد. بنابراین با توجه به جدول فقط دو عامل اول با دارا بودن مقادیر ویژه بزرگتر از 1 انتخاب می شوند. همچنین توجه کنید که این دو عامل به ترتیب 61.6750 و 31.7925 درصد از واریانس کل اقلام را به خود اختصاص می دهند، و روی هم رفته این دو عامل حدود 93 درصد از کل تغییرات اقلام پنجگانه را توضیح می دهند.راهی جایگزین جهت انتخاب عوامل مهم یک تحقیق استفاده از نمودار سنگریزه عناصر در مقابل مقادیر ویژه است. جهت درک این نمودار تصور کنید که در كوهستاني قرار دارید. در صورتيكه در يك كوهستان واقعي قرار بگيريد
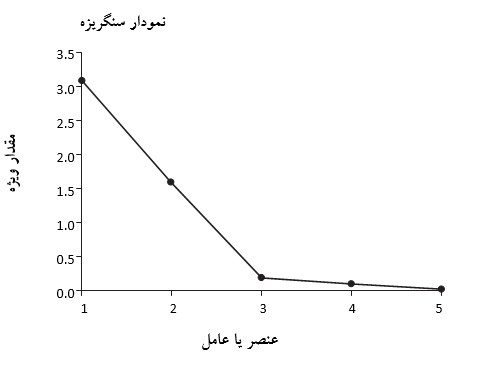
شكل 22.1. نمودار سنگريزه مقادير ويژه
سنگريزه ها از قسمت هاي شيب دار كوه به سمت پايين سقوط كرده و جايي كه شيب كوه مسطح مي شود، قرار مي گيرند. در شكل 22.1 مشاهده مي كنيد كه اين مسئله در مورد عنصر 3 رخ داده است و عوامل قبل از آن حالت يك آرنج را در نمودار گرفته اند. با توجه به نمودار سنگريزه مي توان به اهميت دو عامل پي برد، كمااينكه مقادير ويژه بدست آمده در جدول بخش قبل نيز حمايت كننده اين دو عامل است.
در جدول بعد همبستگي اقلام پرسشنامه با دو عامل بدست آمده در بخش قبل آورده شده اند (چنانكه در جدول نشان داده شده است بند (الف) به عنوان جزئي از ماتريس است). توجه كنيد همبستگي سؤال 1 با عامل 1 و 2 به ترتيب برابر با 0.4105 و 0.8850 است.
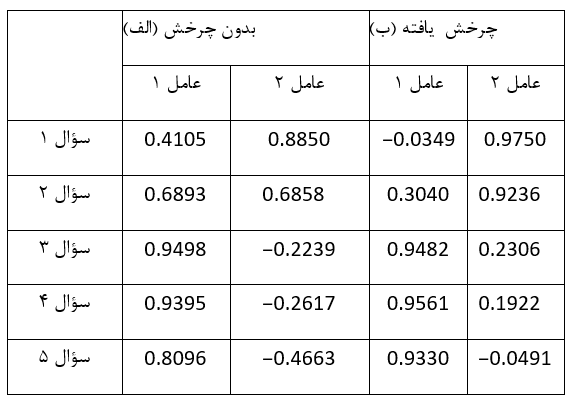
مقادير بدون چرخش اطلاعاتي از ميزان ارتباط ميان متغیرها و عوامل ارائه مي دهد؛ با استفاده از برخي روش ها مانند چرخش مي توان به اطلاعات واضح تري دست يافت. اين روش جهت ارتباط بهتر با متغیرها، عوامل بدست آمده را حول خطي چرخش مي دهد. تصور كنيد نقاشي اي را روي ديوار نصب كرده ايد و در اين حين متوجه مي شويد نقاشي تا حدودي كج است و بنابراين آن را حول خطي چرخانده تا صاف شود. چرخاندن عوامل هم تا حدودي مشابه اين امر است. در اين روش تغييرات بنيادي در ساختار همبستگي ها ايجاد نمي شود و سعي مي شود به گونه اي ساده تر بيان شوند.
روش هاي مختلفي براي چرخاندن وجود دارد. در بخش دوم ماتریس عناصر، یعنی در قسمت (ب) ماتریس بالا، مقادیر بدست آمده پس از اعمال اثر چرخش واریمکس (زیر نویس شود varimax rotation) آورده شده اند. این روش تلاش می کند تا عوامل را در ستونهای ماتریس عناصر به بهترین حالت ممکن کنار هم گردآوری کند. پس از اجرای چرخش درک واضحتری از متغیرها خواهیم داشت و با توجه به جدول متوجه می شویم که سؤالات 1 و 2 بار عاملی نسبت به عامل 2 و سؤاالهای 3، 4 و 5 بار عاملی نسبت به عامل 1 دارند. سؤال 2 نسبت به هر دو عامل بار عاملی دارد، اما پس از چرخش می بینیم که بار عاملی آن نسبت به عامل 2 قویتر است.
اکنون می خواهیم بدانیم چه مقدار از واریانس هر کدام از متغیرها توسط دو عامل ایجاد شده تبیین می شوند. جهت بدست آوردن این مقادیر در مورد هر کدام از متغیرها مربع همبستگی های بدست
آمده را با هم جمع می کنیم. حال جهت محاسبه این مقدار از کدامیک از مقادیر بدون چرخش و یا چرخش یافته می بایست استفاده کرد؟ پاسخ این است که تفاوتی ندارد؛ چرخش تغییری در عوامل ایجاد نمی کند. مشاهده می کنید که در بخش بعد از مقادیر چرخش یافته استفاده شده است در حالیکه در صورت تمایل می توانید از مقادیر بدون چرخش استفاده کرد.
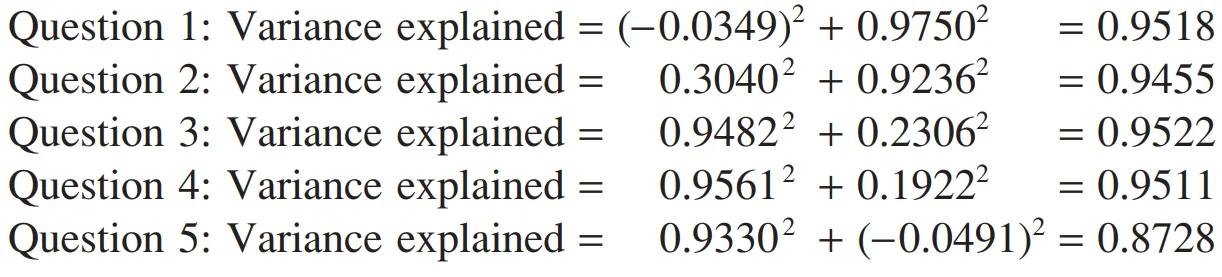
به خاطر آورید که در هر کدام از متغیرها واریانس به مقدار 1 استاندارد شد، بنابراین عوامل بدست آمده توانایی توضیح دادن مقیاس گسترده ای از تغییرات داده ها را خواهند داشت. اعداد بدست آمده در ستون آخر مقادیر بالا اشاره به مقادیر همه داشت (communalities)، که مقیاسی از تغییرات یک متغیر در کنار سایر متغیرها می باشد، دارد و در مورد مثال ذکر شده این مقادیر به نوعی عوامل بدست آمده را حمایت کرده اند.
در نهایت نتیجه می گیریم که تحلیل عاملی روابط میان متغیرها در داده ها را آزمون کرده و مجموعه ای از عوامل را ایجاد می کند. چنانچه یافت شوند که توانایی تبیین بخش زیادی از تغییرات متغیرها را داشته باشند، استدلال می کنیم که متغیرهای مذکور قابلیت خلاصه شدن به عوامل کمتری که قابل استخراج هستند را دارند. در مورد مثال ذکر شده تحلیل عاملی دو فاکتور را شناسایی کرد، یک مربوط به سؤالهای 3، 4 و 5 بود و دیگری سؤالهای 1 و 2 را در برداشت.
جهت مشاهده جزئيات بيشتر در ارتباط با چگونگی انجام تحلیل عاملی با استفاده از بسته کامپیوتری آماري SPSS به فصل 17كتاب هينتون و ديگران (2004) مراجعه شود.
آناليز واريانس چند متغيره
در بسياري از موارد در تحليل داده ها با توجه به مقياس هاي در دسترس، علاقه مند به مقايسه گروه هاي مختلف شركت كنندگان هستيم. به عنوان مثال در پرسشنامه اي قصد داريم فرضياتي چون “آيا افراد جوان شادتر از افراد مسن هستند؟” را بررسي كنيم. در صورتيكه داده ها در مورد مقياسي كه در حال كار كردن با آن هستيم شامل عددي كلي باشند، از آنها مي توان جهت تحليل تك متغيره (زير نويس شود univariate) استفاده كرد؛ بدين معني كه در آن متغير وابسته نمرات شركت كنندگان در آزمون مورد تحليل قرار مي گيرد. بنابراين تحليل تك متغيره مانند آزمون تي (زمانيكه فقط دو گروه وجود داشته باشد) و يا آناليز واريانس (زمانيكه بيش از دو گروه موجود باشند) انجام مي شود. با این حال با وجود ترکیبی از نمرات پرسشنامه، نمی توان سؤالهای متفاوت موجود در آن را به عنوان متغیرهای مستقل جداگانه تحلیل کرد و راهی برای انجام این کار چندین مرتبه استفاده از آزمون تك متغيره در مورد هر کدام از متغیرهای وابسته به صورت جداگانه است. مشکلی که این روش وجود دارد، افزایش تعداد آزمونهای بکار برده شده و در ادامه افزایش خطای نوع اول است.
با استفاده از آنالیز واریانس چند متغیره می توان بر این مشکل فائق آمد؛ این روش به ما اجازه می دهد که بیش از یک متغیر وابسته را در تحلیل هایمان وارد کنیم. در جدول زیر مشاهده می کنید که سؤال جدیدی با عنوان میزان درآمد به پرسشنامه افزوده شده است و بیانگر سطح درآمد شرکت کنندگان است.
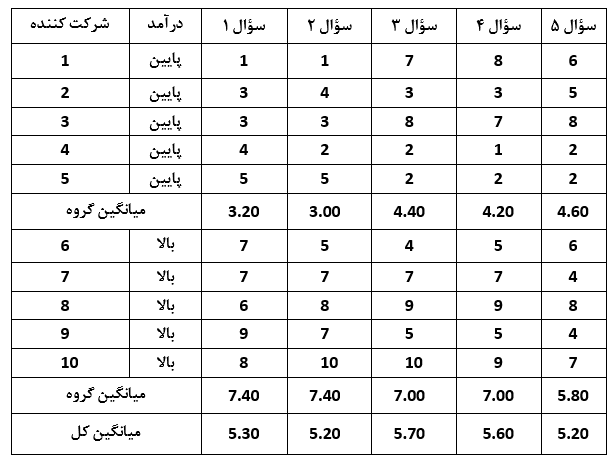
اکنون با داشتن متغیر وابسته تکی با عنوان “درآمد” قادریم اثر آن را بر روی هر کدام از سؤالها در قالب پنج آزمون تی جداگانه بررسی کنیم. راهی دیگر جهت تحلیل داده ها استفاده از آنالیز واریانس چند متغیره است که در آن پنج سؤال به عنوان پنچ متغیر مستقل در نظر گرفته می شوند.
آنالیز واریانس چند متغیره نیز مشابه با آنالیز واریانس نیاز به فرضیاتی چون نرمال بودن جمعیت تحت بررسی و همچنین همگنی واریانسها دارد. از آنجا که با طرحی چند متغیره روبرو هستیم، لذا فرض همگنی کواریانس نیز ایجاد می شود، بدین معنی که همبستگی ها در تمامی سطوح متغیرها یکسان باشد.
منطق آنالیز واریانس چند متغیره مشابه با آنالیز واریانس ساده است با این تفاوت که محاسبات این روش مستلزم جبر ماتریسهات که فراتر از محدوده این کتاب است (انتهای فصل 23 را مشاهده کنید). جدول داده ها در واقع ماتریسی از پاسخهاست. در آنالیز واریانس چند متغیره متغیرهای وابسته در قالب یک متغیر وابسته ترکیبی به آزمون بررسی اثر متغیرهای مستقل می پردازد. در آنالیز واریانس شاخص هایی مانند مجموع مربعات تیمار و مجموع مربعات خطا داشتیم و با داشتن آنها میانگین مربعات (یا واریانس) در مورد تیمارها و همچنین میانگین مربعات در ارتباط با خطا را محاسبه کرده و در نهایت نسبت واریانس (یا مقدار F) محاسبه می شد. مجموع مربعات در مورد آنالیز واریانس چند متغیره نیز به کار می رود با این تفاوت که در محاسبات حاصلضرب متقاطع نیز وجود دارد.

حاصلضرب متقاطع مقیاسی از چگونگی تغییرات دو متغیر است. همانطور که مجموع مربعات قلب تپنده آنالیز واریانس ساده است، ماتریسی با عنوان “مجموع مربعات و حاصلضرب متقاطع” (SSCP) (زیر نویس شود sums of squares and cross-products) در دل محاسبات آنالیز واریانس چند متغیره جای دارد و از این رو قادر است اثر متغیر مستقل را در ترکیبی از چندین متغیر وابسته بدست آورد.
دقیقاً مشابه آنچه که در آنالیز واریانس مجموع مربعات به دو بخش مجموع مربعات بین گروهی و مجموع مربعات خطا تقسیم می شد در روش نیز ماتریس کلی مجموع مربعات و حاصلضرب متقاطع (T) به همان صورت ماتریسی به دو بخش اثر بین گروهی تیماری (B) و خطا (E) که در واقع همان اثر درون گروهی است تقیسم می شود. اکنون قصد داریم دو شاخص آخر معرفی شده را با هم مقایسه کنیم. روش مقایسات B و E مشابه مجموع مربعات در آنالیز واریانس است. (در حقیقت در آنالیز واریانس به جای مجموع مربعات، از میانگین مربعات برای مقایسات استفاده می شد ولی کلیت کار مشابه است.) از آنجاییکه B و E عدد نبوده و ماتریس هستند راهی ریاضی جهت تعیین تغییرات مقادیر استفاده از دترمینان (determinant) ماتریس است. به عنوان مثال دترمینان ماتریس B به صورت بوده و به صورت یک عدد بیان می شود و به عنوان یک آماره اجازه ارزیابی معنی دار بودن فرضیات تحت بررسی را می دهد. (به نظر می رسد که مبحث ماتریس در ریاضیات یک مفهوم جدید باشد اما با توجه به شباهت منطق آنالیز واریانس چند متغیره با آنالیز واریانس توضیح آن چندان سخت نیست.)
در رابطه با روش آنالیز واریانس چند متغیره آماره های زیادی معرفی شده اند اما معروفترین آنها که کاربرد زیادی دارد آماره لامبدای ویلکس است و به صورت زیر محاسبه می شود:

همچنین چنانچه ذکر شد می توان به صورت جداگانه هر کدام از سؤالها را با وجود عامل مستقل در قالب طرح آنالیز واریانس ساده آزمون کرده و اثر درآمد را بر آنها به صورت جداگانه بررسی کرد. این روش نتایج زیر را منتج می شود:
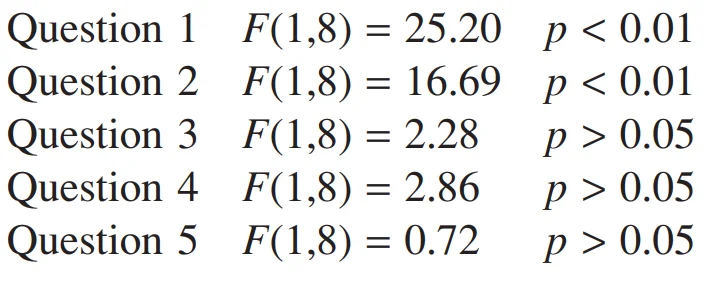
با توجه به مقادیر بدست آمده ملاحظه می کنیم که درآمد اثری معنی دار روی دو سؤال اول دارد ولی این اثر در مورد سه مورد بعدی معنی دار نیست.
زمانی که تعدادی آزمون روی داده های مشابه انجام می شود، اغلب سطح معنی داری به خاطر افزایش خطای نوع اول، تصحیح شده و به آن تصحیح بون فرونی (Bonferroni) گفته می شود که از تقسیم سطح معنی داری بخش بر تعداد آزمون ها بدست می آید؛ بنابراین با وجود پنج آزمون به جای انتخاب p = 0.05، سطح معنی داری p = 0.01 را انتخاب می کنیم (فصل 12 را مشاهده کنید). در این مثال مشاهده کردیم که حتی با وجود معیاری دقیق تر برای معنی داری، باز هم نتایج بدست آمده از آنالیز واریانس تک متغیره مشابه حالت چند متغیره شد.
جهت مشاهده جزئيات بيشتر در ارتباط با چگونگی انجام آنالیز واریانس چند متغیره با استفاده از بسته کامپیوتری آماري SPSS به فصل 12كتاب هينتون و ديگران (2004) مراجعه شود.
تحلیل تابع تشخیص
تحلیل تابع تشخیص مانند عکس آنالیز واریانس چند متغیره عمل می کند و چنانچه مشاهده شد آنالیز واریانس چند متغیره اثر یک یا بیش از یک متغیر مستقل را روی تعدادی متغیر وابسته بررسی می کند، در حالیکه تحلیل تابع تشخیص آزمون می کند کدامیک از ترکیبات متغیرهای مستقل بهترین پیش بینی کننده متغیر وابسته است. در حقیقت تحلیل تابع تشخیص تحلیلی مفید پس از معنی داری مقادیر مستقل اندازه گیری شده در آنالیز واریانس چند متغیره است، کمااینکه این روش نیز محاسباتی مانند آنچه در آنالیز واریانس چند متغیره انجام شد نظیر مجموع مربعات و حاصلضرب متقاطع دارد و به همین دلیل است که نیازمند فرضیاتی مشابه با آنالیز واریانس چند متغیره می باشد.
در حقيقت تحليل تابع تشخيص توابع مورد نياز متغيرهاي مستقل را جهت تشخيص ميان سطوح متغير وابسته ايجاد مي كند. جهت انجام اين تحليل متغير وابسته و متغيرهاي مستقل جايگزين يكديگر شده و پنج سؤال مطرح شده به عنوان متغيرهاي مستقل و درآمد به عنوان متغير وابسته لحاظ خواهد شد. حال اين سؤال مطرح است كه آيا تابعي وجود دارد كه با استفاده از پنج سؤال موجود بتوان به پيش بيني سطح درآمد افراد پرداخت؟ در صورتيكه فقط دو سطح درآمد وجود داشته باشد (پايين و بالا) تنها يك تابع وجود خواهد داشت و اگر سه يا تعداد بيشتري سطح درآمدي داشته باشيم تعداد بيش از يك تابع ايجاد خواهد شد. زماني كه بيش از يك تابع وجود داشته باشد، هر كدام از آنها بخش مشخصي از تغييرات داده ها را تبيين كرده و از اين توابع مي توان (مشابه با عوامل در تحليل عاملي) جهت بررسي و چگونگي تغييرات توضيح داده شده (و معني داري آن) استفاده كرد.
در صورتيكه مقدار ويژه توابع محاسبه شده بيش از 1 و همبستگي كانوني (canonical correlation) آنها از مقدار 0.6 تجاوز كند، ارزشمند خواهند بود. همبستگي كانوني در حقيقت ميزان همبستگي تابع محاسبه شده با متغير وابسته است و در اين حالت در واقع ضريب همبستگي چندگانه است (R) مي باشد (فصل 21 را مشاهده كنيد). در مثال مذكور شهودي از ميزان قوي بودن تشخيص وجود دارد، زيرا مقدار ويژه و همبستگي كانوني آن به ترتيب برابر با 17.4594 و 0.9725 بدست آمده اند كه هر دو مقاديري قابل توجه مي باشند. معني داري تابع محاسبه شده توسط آماره لامبداي ويلكس مشخص مي شود كه در اين مورد برابر با 0.0542 بدست آمده و مشاهده مي كنيم كه p<0.01؛ در نتيجه تابع محاسبه شده در تشخيص دو سطح درآمدي قوياً معني دار است. بايد توجه داشت كه آماره ويلكس محاسبه شده در اين بخش دقيقاً مشابه آنچه است كه در بخش آناليز واريانس چند متغيره بدست آمده و اين امر نشاندهنده ي ارتباط قوي اين دو روش تحليل است.
از آنجاييكه فقط يك تابع تشخيص داشتيم بنابراين تابع محاسبه شده فرمي مشابه با رگرسيون چند متغيره خواهد داشت. با استفاده از ضرايب تابع تشخيص استاندارد نشده مي توان ضرايب رگرسيوني (محاسبه شده در اين تحليل) را بدست آورد، بنابراين تابع مثال مورد نظر به صورت زير بيان مي شود:
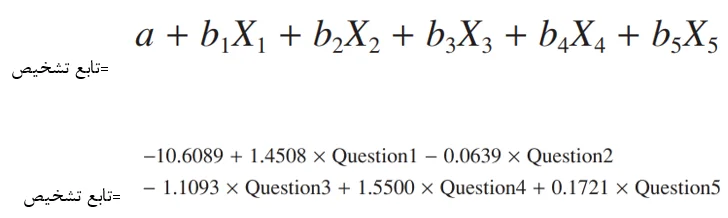
نكته ي قابل ذكر در مورد اين تابع اين است كه زماني كه مقادير عددي سؤالهاي 1 تا 5 در مورد هر كدام از شركت كنندگان وارد معادله شود، خروجي حاصل قابليت دسته بندي فرد و اينكه به كدام يك از طبقات متغير وابسته تعلق دارد را به ما مي دهد (بدين معني كه سطح درآمد آنها را پيش بييني مي كند). با توجه به جدول زير مشاهده خواهيد كرد تابع مذكور توانايي دسته بندي كليه شركت كنندگان را به طور صحيح دارد؛ بدين صورت كه مقدار منفي نشاندهنده ي افراد با درآمد پايين و در مقابل آن، مقدار مثبت بيانگر شركت كنندگاني با درآمد بالاست.
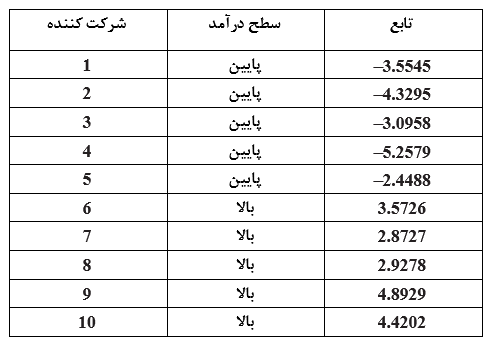
ميانگين مقادير بدست آمده هر تابع براي هر كدام از گروه ها اشاره به گرانيگاه هاي گروهي(centroids) داشته و اطلاعاتي جهت گروهبندي را ارائه مي دهد و در اين مثال اين شاخص ها براير نويس شود مده هر تابع براي هر كدام از گروه ها اشاره به گرانيگاه () درآمد بالاست. بر با -3.7373 و +3.7373 است. با توج به اينكه تعداد شركت كنندگان در دو گروه مساوي است، می توان موقعیت میانه آنها را به عنوان نقطه بحرانی در نظر گرفت (بدین معنی که میانگین آنها برابر با صفر است). (با وجود گروه های نامساوی جهت یافتن نقطه بحرانی، ابتدا با توجه به تعداد هر کدام از نمونه ها به آنها وزنی اختصاص داده و در نهایت موقعیت میانگین وزن داده شده را به عنوان نقطه بحرانی در نظر می گیریم.) اکنون در صورتیکه نتایج حاصل از پاسخ های 1 تا 5 شرکت کننده ای جدید را داشته باشیم، از این تابع جهت پیش بینی گروه درآمدی می توان استفاده کرد.
در صورتیکه تابع محاسبه شده مقداری منفی ارائه دهد فرد مزبور در گروه افرادی با “درآمد پایین” و در صورت مثبت بودن تابع در به گروه “درآمد بالا” تعلق دارد. به عنوان مثال فردی که به سؤالات 1 تا 5 پاسخهای 7، 4، 8، 3 و 5 را داده باشد مقدار تابع محاسبه شده برابر با -4.0728 بوده و پیش بینی می شود که فرد به گروه افراد با درآمد پایین تعلق دارد.
در نهایت مشابه با آنچه در تحلیل عاملی داشتیم و قادر به تشخیص متغیرهایی با بیشترین همبستگی با تابع تشخیص بودیم، در این روش نیز با بررسی ماتریس ساختار که در جدول زیر آمده و همبستگی هر کدام از متغیرها با تابع محاسبه شده را نشان می دهد، به این امر نائل خواهیم گشت. ماتریس ساختار حاوی ضرایب همبستگی برای هر کدام از سؤالها است و با توجه به جدول مشاهده می کنیم که سؤال 1 و 2 بالاترین میزان را به خود اختصاص داده اند و منعکس کننده همان نتیجه ای است که در آنالیز واریانس چند متغیره بدست آمد.
در این مثال خاص مثالی ساده از تحلیل تابع تشخیص را مشاهده کردیم اما طرحهایی پیچیده وجود دارند که در آنها می بایست دو یا بیشتر از دو تابع تشخیص را بیابیم و در نتیجه برای بررسی معنی داری آماره لامبدای ویلکس می بایست الگویی از روابط میان متغیرها یافته شود.
نتیجه گیری
ظهور کامپیوترهای سریع و در دسترس همه بدان معنی است که حتی پیچیده ترین تجزیه و تحلیل های آماری را در مورد داده های پژوهش می توان براحتی با لمس یک دکمه انجام داد. با این حال، نکته تنها انجام دادن تحلیل نیست بلکه اینکه چگونه بتوان آن را انجام داد امری مهمتر است. سؤالی که برای محقق ایجاد می شود این است که آیا درک کافی از تحلیل جهت تصمیم گیری برای بکارگیری مناسب ترین روش در داده های موجود وجود دارد و همچنین آیا قادر است تفسیری صحیح از خروجی تحلیلی که ایجاده شده است ارائه دهد. باید توجه داشت که یک تحلیل ساده و مرتبط قادر است نکات کلیدی پژوهش را به روشی ساده و قابل درک ارائه دهد.
مترجمین: دکتر هدی کامرانی فر – حسن اسکندری نیا




